Какой вид оценки имеет буквенную кодировку. Что такое кодирование и декодирование? Примеры. Способы кодирования и декодирования информации числовой, текстовой и графической
КОДИРОВАНИЕ ИНФОРМАЦИИ
КОДИРОВАНИЕ ИНФОРМАЦИИ
Установление соответствия между элементами сообщения и сигналами, при помощи к-рых эти могут быть зафиксированы.
Пусть В,
,
- множество элементов сообщения, А -
алфавит с символами , Пусть конечная последовательность символов наз. словом в данном алфавите. Множество слов в алфавите А
наз. кодом, если оно поставлено во взаимно однозначное соответствие с множеством В.
Каждое слово, входящее в код, наз. кодовым словом. Число символов в кодовом слове наз. длиной слова. Кодовые слова могут иметь одинаковую или разл. длину. В соответствии с этим код наз. равномерным или неравномерным.
Цели К. и.: представление входной информации в , согласование источников информации с каналом передачи, обнаружение и исправление ошибок при передаче и обработке данных, сокрытие смысла сообщения (криптография) и т. д. Информационные свойства объекта, как правило, таковы, что код может быть представлен наиболее экономным образом. Эту задачу решает кодер источника, удаляя из сообщений избыточность. Дальнейшие этапы прохождения данных - передача по каналу передачи и (или) хранение в запоминающих устройствах - требуют обнаружения и(или) исправления ошибок, возникающих в них вследствие помех. Эти цели достигаются путём корректирующего кодирования, осуществляемого к о-дером канала. Наконец, информации от искажений при обработке в ЭВМ осуществляется применением арифметич. кодов.
Кодирование значений
. Натуральное число N
представлено в позиционной весомозначной системе счисления, если имеет место соотношение

где - цифровой алфавит с п
цифрами, " - веса разрядов, - номера разрядов. Термин "позиционная" означает, что в кодовом представлении (пли просто коде) числа, выражаемом условным равенством
количественный эквивалент, сопоставляемый цифре а l
, зависит и от её расположения в коде. Термин "весомозначная" означает, что каждый разряд имеет p l .
Вес младшего разряда р 0
в цифровой измерительной технике отождествляется с разрешающей способностью аналого-цифрового преобразования. Выбор алфавита А
и системы весов Р
задаёт классификацию позиционных систем счисления (кодирование значений). В естественных системах
и, если n
- основание системы счисления - натуральное число, любое число X
может быть представлено как

Выбор алфавита смещённым: А
= (0, 1, . . ., п
-1), А=(-п-
1, . . ., 1, 0), или симметричным: А = (-п-
1, . . ., -1, 0, 1, . . ., п-
1) позволяет представлять соответственно положительные, отрицательные или любые числа. Симметричная система должна обладать нечётным основанием.
В ЭВМ почти исключительно используется позиционная двоичная смещённая система (n=2) с цифрами (0, 1) и естественным соотношением весов, представляющих ряд чисел
Возможно применение и иного набора цифр, напр. (-1, 1), дающего нек-рые специфические преимущества.
Развиваются двоичные системы, веса разрядов к-рых находятся не в естественном (2), а в более сложном соотношении, образуя, напр., ряд Фибоначчи (или "золотую пропорцию") . Число N
в коде Фибоначчи представляется соотношением
где - числа Фибоначчи, связанные соотношением
Разложение (4) числа N
неоднозначно. Для любого N
существует код, в к-ром не встречается двух следующих подряд нулей, а также код, в к-ром не соседствуют единицы. Эти, а также др. структурные особенности кодов Фибоначчи и "золотых" кодов делают их удобными для построения самокорректирующихся преобразователей, запоминающих и вычислит. устройств, сервоприводов с цифровым управлением и т. п.
Троичные системы счисления наиб. экономичны в том смысле, что именно в троичном коде определ. кол-вом знаков может быть выражено наибольшее разнообразие чисел. Есть основание полагать, что в будущем именно в силу указанного свойства троичная симметричная система кодирования с цифрами (-1, 0, 1) займёт в вычислит. технике доминирующее место. Проблемой остаётся создание элементов, реализующих ф-ции базиса в троичной логике: троичный инвертор и троичные НЕ-И или троичные НЕ-ИЛИ (см. Логические схемы),
Непозиционные коды применяют в специализированных измерит. и вычислит. устройствах . Простейший из непозиционных - унитарный код можно получить, положив в (2) n
=1 и р 0
=1. В нём число N
представляется как N
=n
+l - последовательно суммируемые единицы. Так работают, напр., счётчики импульсов.
Среди систем непозиционного кодирования выделяется система счисления в остаточных классах (СОК). Число N
в СОК представляется в виде упорядоченного набора остатков (вычетов) по взаимно простым основаниям p 1
, . . ., р п;
, где - наименьший вычет N
по модулю р
. Система оснований р 1
, р 2
, . . ., р п
определяет диапазон представления чисел P=р 1 , р 2 ,
. . ., р п.
В СОК арифметич. операции производятся независимо по каждому основанию и это позволяет существенно увеличить их выполнения. В СОК удобен контроль операций, т. к. ошибки локализованы в пределах оснований. Специфичным для вычислит. устройств, работающих в СОК, является применение табличной арифметики: значения ф-ции, подлежащей вычислению, заранее заносятся в таблицу, а затем извлекаются при поступлении значений операндов.
Эффективное кодирование источника информации имеет целью согласование информационных свойств источника информации (ИИ) п канала передачи. Предполагается, что ИИ выдаёт на выходе , состоящее из букв m
-буквенного алфавита
причём появление букв статистически независимо и подчинено распределению
Источник характеризуется энтропией на символ
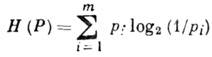
Энтропия ![]() имеет смысл неопределённости относительно появления на выходе ИИ очередного символа. Равенство Н(Р)=0
достигается при вырожденном распределении Р,
т. к. сообщение
имеет смысл неопределённости относительно появления на выходе ИИ очередного символа. Равенство Н(Р)=0
достигается при вырожденном распределении Р,
т. к. сообщение
при этом детерминированно; равенство ![]() достигается при равновероятном появлении - ситуация наибольшей неопределённости. При m=2 и равномерном появлении букв а 1
и а 2
энтропия максимальна и Н(Р) = 1.
Эта величина - неопределённость при равновероятном выборе из двух альтернатив используется как единица кол-ва энтропии - 1 .
достигается при равновероятном появлении - ситуация наибольшей неопределённости. При m=2 и равномерном появлении букв а 1
и а 2
энтропия максимальна и Н(Р) = 1.
Эта величина - неопределённость при равновероятном выборе из двух альтернатив используется как единица кол-ва энтропии - 1 .
Каждый способ кодирования характеризуется ср. числом L(Р
)букв выходного алфавита, приходящихся на одну букву входного алфавита А т.
Для алфавитного кодирования ![]() - длина слова в алфавите В r .
Если кодирование взаимно однозначно, то
- длина слова в алфавите В r .
Если кодирование взаимно однозначно, то

Величина I(P
) = L
(P
)- Н r (Р
)наз. избыточностью кодирования при распределении Р.
Задача состоит в отыскании в заданном классе взаимно однозначных кодирований кодирования, обладающего мин. величиной I(P).
Существование минимума и его значение устанавливаются теоремой Шеннона для канала без шума, гласящей, что для источника с конечным алфавитом А т
с энтропией Н(Р
)можно так приписать кодовые слова буквам источника, что ср. длина кодового слова L (Р
)будет удовлетворять условиям
Оптимальным считается такой код, что никакой другой не обеспечит меньшего значения L(Р).
Конструктивная процедура отыскания оптим. кода для кодирования данного множества сообщений предложена в 1952 Д. Хафменом (D. R. Huffman). Идея заключается в том, что буквы алфавита А т
упорядочиваются по и более вероятным приписываются более короткие кодовые слова. Код Хафмена обладает . свойствами: слово, соответствующее наименее вероятному сообщению, имеет наибольшую длину; два наименее вероятных сообщения кодируются словами одинаковой длины, одно из к-рых оканчивается нулём, а другое - единицей (r=2).
Оптимальное равномерное кодирование.
Пусть источник с двухбуквенным алфавитом и генерирует слова длиной l.
Относительно всего множества из 2 l
слов (словаря источника) существует утверждение, что при и достаточно больших l
словарь источника распадается на два подмножества: группу из равновероятных слов (рабочий словарь источника) и группу слов с суммарной вероятностью, близкой к нулю ("нетипичные" последовательности). Здесь Н(Р) -
энтропия на символ источника. Доля слов рабочего словаря весьма мала и с увеличением l
стремится к нулю. Идея равномерного, или блокового, кодирования заключается в том, что кодер, получая на входе слова источника, сопоставляет кодовые слова лишь словам из рабочего словаря, кодируя все остальные одним словом, имеющим смысл ошибки. Вероятность ошибки может быть произвольно уменьшена увеличением длины слова источника. При этом объём кодируемых слов требует символов кодового слова. Поскольку слова рабочего словаря практически равновероятны, равновероятны будут и кодовые слова, а энтропия на символ кодового слова будет близка к 1 биту. Кодер, т. о., выдаёт слова длиной , экономя за счёт того, что "догружает" каждый символ до максимально возможной информационной нагрузки в 1 бит.
Кодирование источника приобретает новое значение в связи с необходимостью "сжатия" информационных массивов данных в базах и банках данных. Массивы организационной, экономич., измерит. информации имеют столь большую избыточность, что допускают , доходящее до 80-85%. Развитые системы управления базами данных (СУБД) имеют спец. программы (утилиты) анализа, сжатия и восстановления текста, работающие на принципах, изложенных выше.
Корректирующее кодирование информации.
Его целью является обнаружение и (или) исправление ошибок в кодовых словах, возникших при передаче информации по каналу с шумом. Коррекция искажений возможна за счёт введения избыточности в систему передачи. При этом из всего множества слов кодера канала N 0
лишь N
будет соответствовать передаваемым сообщениям (разрешённые слова). Теоретически при этом доля обнаруженных ошибок не превыси 1-N/N 0 .
Предполагается, что информационное слово U
= (u 1
, . . ., u
n), где u j
=0, 1, поступает на вход кодера канала (в дальнейшем - кодера), ставящего ему в соответствие кодовое слово X (х 1 , . .
., x l),
,
Кодер, т. о., добавляет по определ. правилу к слову U
группу из k=l-n
избыточных (корректирующих) разрядов. Кодовое слово X
поступает в канал с шумом, где помеха искажает нек-рые из символов х i .
Принятое на выходе канала слово Y
= ( у 1 , . . ., у 2
) поступает на декодер, восстанавливающий (с пек-рым приближением) слово X.
С кодовыми словами оперируют как с векторами в линейном векторном пространстве с метрикой Хэмминга, задающей расстояние между векторами
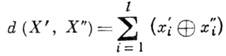
Теорема Шеннона для каналов с шумом, утверждающая, что при помощи подходящих кодов можно передавать информацию так, чтобы вероятность ошибки после декодирования была произвольно малой при условии, что скорость передачи не превосходит пропускной способности канала связи, неконструктивна: она не указывает способа построения кода. При конструировании кода решающее значение имеет выбор модели возникновения ошибок в передаваемом слове.
Наиб. распространена модель симметричного канала с равновероятными ошибками разл. типов - перехода, напр., символа 0 в 1 и 1 в 0.
Специфична модель канала "со стиранием". Выходной алфавит такого канала содержит спец. символ стирания, в к-рый и переходят символы входного алфавита при возникновении ошибки подобного типа.
Выдвигаются разл. предположения относительно распределения ошибок в передаваемой последовательности символов (кодовом слове). Возможна модель независимых ошибок (канала без памяти), модель сгруппированных ошибок (пачек ошибок), ошибок, расположенных на определ. расстоянии друг от друга, и т. д. Распространены предположения о предельной кратности ошибок в кодовых словах .
В рамках последнего предположения корректирующая способность кода оценивается числом ошибок, обнаруживаемых и (или) исправляемых с его помощью в кодовых словах. Предполагается, что в канале с X
посимвольно суммируется (по mod 2) шумовой вектор Z,
образуя слово . Кратность возникающей в результате ошибки совпадает с числом единиц (весом Хэмминга) в Z.
В векторе из l
элементов не более чем r
единиц могут быть размещены способами.
Это - то разнообразие ошибок, к-рое может возникнуть при передаче.
Основной характеристикой кода, определяющей его корректирующую способность по отношению к независимым ошибкам, является кодовое расстояние. Кодовое расстояние является наименьшим хэмминговым расстоянием между всевозможными словами = ( , . . ., ) и кода. Для того чтобы код обнаруживал все комбинации из s
ошибок и исправлял все комбинации из t
ошибок, необходимо и достаточно, чтобы кодовое расстояние было равно s
+t
+1.
Широкий класс кодов для симметричного канала составляют линейные (групповые) коды , напр, коды Хэмминга, широко применяющиеся для защиты информации в основной памяти ЭВМ. Код Хэмминга обладает кодовым расстоянием d=3,
исправляет однократные ошибки и обнаруживает двукратные. Он имеет проверочные разряды, расположенные в позициях с номерами 2°, 2, 2 2 , . . . Линейный код задаётся парой матриц: порождающей , , и проверочной . Строки порождающей матрицы - линейно независимые векторы, образующие базис пространства, содержащего 2 n элементов - кодовых слов. Каждая из строк проверочной матрицы ортогональна строкам , , и
Кодер линейного кода образует кодовые слова по правилу X T =U T G.
Модель искажений предполагает, что в канале с X
посимвольно суммируется шумовой вектор Z,
образуя слово Y=X+Z.
Идея декодирования заключается в образовании произведения S T =Y T Н T ,
называемого синдромом. Равенство S
= 0 означает, что Z=0,
либо ошибка относится к необнаруживаемым. Синдром имеет 2 k -1 ненулевых реализаций, каждая из к-рых может быть использована для указания на произошедшую ошибку.
Циклич. коды входят как подкласс в групповые коды. В них вместе со словом X
входят и все его цик-лич. перестановки. Кодовые слова образуются как произведение двух полиномов: U (Е
)степени п-
1, коэф. к-рого составляют информационное слово U,
и порождающего g (Е
)степени l-п,
неприводимого и делящего без остатка двучлен (1+E l
). Декодирование заключается в делении принятого слова (полинома) на g(E).
Наличие ненулевого остатка укажет на присутствие ошибки. Циклич. коды, как правило, несистематические.
Спец. циклич. коды предназначены для обнаружения и исправления пачек ошибок, напр, коды Файра, определяемые порождающими полиномами вида g(E) = =p(E)(E c +1),
где р(Е) -
неприводимый полином, а величина с
определяется длиной исправляемых и обнаруживаемых пачек ошибок.
Пачки ошибок характерны для запоминающих устройств с магн. носителями, в частности для накопителей на магн. дисках (НМД) совр. ЭВМ (см. Памяти устройства).
Для защиты данных в НМД поэтому широко используется К. и. циклич. кодами, осуществляемое аппаратными средствами.
Арифметические коды
предназначены для обнаружения ошибок, возникших при выполнении арифметич. операций на ЭВМ. В теории арифметич. кодирования вводятся понятия веса, расстояния и ошибки, отличные от хэмминговых. Арифметич. вес числа определяется как мин. число слагаемых в представлении числа в виде , ![]() . Ошибки, в результате к-рых величина числа изменяется на , г"=0, 1, 2, . . ., наз. арифметическими. Арифметич. расстояние между N 1
и N 2 -
арифметич. вес разности , равно кратности ошибки, переводящей число N 1
в N 2 ,
и определяет корректирующую способность арифметич. кода подобно расстоянию Хэмминга.
. Ошибки, в результате к-рых величина числа изменяется на , г"=0, 1, 2, . . ., наз. арифметическими. Арифметич. расстояние между N 1
и N 2 -
арифметич. вес разности , равно кратности ошибки, переводящей число N 1
в N 2 ,
и определяет корректирующую способность арифметич. кода подобно расстоянию Хэмминга.
В распространённых AN-
кодахкодирование числа N
- операнда - осуществляется умножением его на специально подобранный множитель А.
Так, 3А-код, имея кодовое расстояние 2, обнаруживает одиночные ошибки путём деления суммы на 3. Ошибки обнаруживаются при ненулевом остатке: величина арифметич. ошибки 2 i
не делится на 3 нацело. Кроме одиночных при A=3 обнаруживается и часть двойных ошибок - те, при к-рых правильный и ошибочный результат имеет несовпадающие остатки от деления на 3.
Криптография осуществляется путём подстановки, когда каждой букве шифруемого сообщения ставится в соответствие определ. символ (напр., др. буква), либо путём перестановки, когда буквы внутри искусственных блоков текста меняются местами, либо комбинацией этих методов. Шенноном показано, что возможны криптограммы, не поддающиеся расшифровке за приемлемое .
Лит.:
1) Стахов А. П., Введение в алгоритмическую теорию измерения, М., 1977; его же, Коды золотой пропорции, М., 1984; 2) Акушский И., Юдицкий Д., Машинная арифметика в остаточных классах, М., 1968; 3) Г а л-л а г е р Р., Теория информации и надежная связь, пер. с англ., М., 1974; 4) Д а д а е в Ю. Г., Теория арифметических кодов, М., 1981; 5) Аршинов М. Н., Садовский Л. Е., Коды и математика, М., 1983. Л. Н. Ефимов.
Физическая энциклопедия. В 5-ти томах. - М.: Советская энциклопедия . Главный редактор А. М. Прохоров . 1988 .
Смотреть что такое "КОДИРОВАНИЕ ИНФОРМАЦИИ" в других словарях:
кодирование информации - Процесс преобразования и (или) представления данных. [ГОСТ 7.0 99] Тематики информационно библиотечная деятельность EN information coding FR codage de l’information … Справочник технического переводчика
Мы познакомились с системами счисления - способами кодирования чисел. Числа дают информацию о количестве предметов. Эта информация должна быть закодирована, представлена в какой-то системе счисления. Какой из известных способов выбрать, зависит от решаемой задачи.
До недавнего времени на компьютерах в основном обрабатывалась числовая и текстовая информация. Но большую часть информации о внешнем мире человек получает в виде изображения и звука. При этом более важным оказывается изображение. Помните пословицу: “Лучше один раз увидеть, чем сто раз услышать”. Поэтому сегодня компьютеры начинают всё активнее работать с изображением и звуком. Способы кодирования такой информации будут обязательно нами рассмотрены.
Двоичное кодирование числовой и текстовой информации.
Любая информация кодируется в ЭВМ с помощью последовательностей двух цифр - 0 и 1. ЭВМ хранит и обрабатывает информацию в виде комбинации электрических сигналов: напряжение 0.4В-0.6В соответствует логическому нулю, а напряжение 2.4В-2.7В - логической единице. Последовательности из 0 и 1 называются двоичными кодами
, а цифры 0 и 1 - битами
(двоичными разрядами). Такое кодирование информации на компьютере называется двоичным кодированием
. Таким образом, двоичное кодирование - это кодирование с минимально возможным числом элементарных символов, кодирование самыми простыми средствами. Тем оно и замечательно с теоретической точки зрения.
Инженеров двоичное кодирование информации привлекает тем, что легко реализуется технически. Электронные схемы для обработки двоичных кодов должны находиться только в одном из двух состояний: есть сигнал/нет сигнала
или высокое напряжение/низкое напряжение
.
ЭВМ в своей работе оперируют действительными и целыми числами, представленными в виде двух, четырёх, восьми и даже десяти байт. Для представления знака числа при счёте используется дополнительный знаковый разряд
, который обычно располагается перед числовыми разрядами. Для положительных чисел значение знакового разряда равно 0, а для отрицательных чисел - 1.
Для записи внутреннего представления целого отрицательного числа (-N) необходимо:
1) получить дополнительный код числа N заменой 0 на 1 и 1 на 0;
2) к полученному числу прибавить 1.
Так как одного байта для представления этого числа недостаточно, оно представлено в виде 2 байт или 16 бит, его дополнительный код: 1111101111000101, следовательно, -1082=1111101111000110.
Если бы ПК мог работать только с одиночными байтами, пользы от него было бы немного. Реально ПК работает с числами, которые записываются двумя, четырьмя, восемью и даже десятью байтами.
Начиная с конца 60-х годов компьютеры всё больше стали использоваться для обработки текстовой информации. Для представления текстовой информации обычно используется 256 различных символов, например большие и малые буквы латинского алфавита, цифры, знаки препинания и т.д. В большинстве современных ЭВМ каждому символу соответствует последовательность из восьми нулей и единиц, называемая байтом
.
Байт – это восьмиразрядная комбинация нулей и единиц.
При кодировании информации в этих электронно-вычислительных машинах используют 256 разных последовательностей из 8 нулей и единиц, что позволяет закодировать 256 символов. Например большая русская буква «М» имеет код 11101101, буква «И» - код 11101001, буква «Р» - код 11110010. Таким образом, слово «МИР» кодируется последовательностью из 24 бит или 3 байт: 111011011110100111110010.
Количество бит в сообщении называется информационным объёмом сообщения.
Это интересно!
Первоначально в ЭВМ использовался лишь латинский алфавит. В нём 26 букв. Так что для обозначения каждой хватило бы пяти импульсов (битов). Но в тексте есть знаки препинания, десятичные цифры и др. Поэтому в первых англоязычных компьютерах байт - машинный слог - включал шесть битов. Затем семь - не только чтобы отличать большие буквы от малых, но и для увеличения числа кодов управления принтерами, сигнальными лампочками и прочим оборудованием. В 1964 году появились мощные IBM-360, в которых окончательно байт стал равен восьми битам. Последний восьмой бит был необходим для символов псевдографики.
Присвоение символу конкретного двоичного кода - это вопрос соглашения, которое фиксируется в кодовой таблице. К сожалению, существует пять различных кодировок русских букв, поэтому тексты, созданные в одной кодировке, не будут правильно отражаться в другой.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией, 8 битный»). Наиболее распространённая кодировка - это стандартная кириллическая кодировка Microsoft Windows, обозначаемая сокращением СР1251 («СР» означает «Code Page» или «кодовая страница»). Фирма Apple разработала для компьютеров Macintosh собственную кодировку русских букв (Мас). Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка кодировку ISO 8859-5. Наконец, появился новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, и поэтому с его помощью можно закодировать не 256 символов, а целых 65536.
Все эти кодировки продолжают кодовую таблицу стандарта ASCII (Американский стандартный код для информационного обмена), кодирующую 128 символов.
Таблица символов ASCII:
| код | символ | код | символ | код | символ | код | символ | код | символ | код | символ |
| 32 | Пробел | 48 | . | 64 | @ | 80 | P | 96 | " | 112 | p |
| 33 | ! | 49 | 0 | 65 | A | 81 | Q | 97 | a | 113 | q |
| 34 | " | 50 | 1 | 66 | B | 82 | R | 98 | b | 114 | r |
| 35 | # | 51 | 2 | 67 | C | 83 | S | 99 | c | 115 | s |
| 36 | $ | 52 | 3 | 68 | D | 84 | T | 100 | d | 116 | t |
| 37 | % | 53 | 4 | 69 | E | 85 | U | 101 | e | 117 | u |
| 38 | & | 54 | 5 | 70 | F | 86 | V | 102 | f | 118 | v |
| 39 | " | 55 | 6 | 71 | G | 87 | W | 103 | g | 119 | w |
| 40 | ( | 56 | 7 | 72 | H | 88 | X | 104 | h | 120 | x |
| 41 | ) | 57 | 8 | 73 | I | 89 | Y | 105 | i | 121 | y |
| 42 | * | 58 | 9 | 74 | J | 90 | Z | 106 | j | 122 | z |
| 43 | + | 59 | : | 75 | K | 91 | [ | 107 | k | 123 | { |
| 44 | , | 60 | ; | 76 | L | 92 | \ | 108 | l | 124 | | |
| 45 | - | 61 | < | 77 | M | 93 | ] | 109 | m | 125 | } |
| 46 | . | 62 | > | 78 | N | 94 | ^ | 110 | n | 126 | ~ |
| 47 | / | 63 | ? | 79 | O | 95 | _ | 111 | o | 127 | DEL |
Двоичное кодирование текста происходит следующим образом: при нажатии на клавишу в компьютер передаётся определённая последовательность электрических импульсов, причём каждому символу соответствует своя последовательность электрических импульсов (нулей и единиц на машинном языке). Программа драйвер клавиатуры и экрана по кодовой таблице определяет символ и создаёт его изображение на экране. Таким образом, тексты и числа хранятся в памяти компьютера в двоичном коде и программным способом преобразуются в изображения на экране.
Двоичное кодирование графической информации.С 80-х годов бурно развивается технология обработки на компьютере графической информации. Компьютерная графика широко используется в компьютерном моделировании в научных исследованиях, компьютерных тренажёрах, компьютерной анимации, деловой графике, играх и т.д.
Графическая информация на экране дисплея представляется в виде изображения, которое формируется из точек (пикселей). Всмотритесь в газетную фотографию, и вы увидите, что она тоже состоит из мельчайших точек. Если это только чёрные и белые точки, то каждую из них можно закодировать 1 битом. Но если на фотографии оттенки, то два бита позволяет закодировать 4 оттенка точек: 00 - белый цвет, 01 - светло-серый, 10 - тёмно-серый, 11 - чёрный. Три бита позволяют закодировать 8 оттенков и т.д.
Количество бит, необходимое для кодирования одного оттенка цвета, называется глубиной цвета.
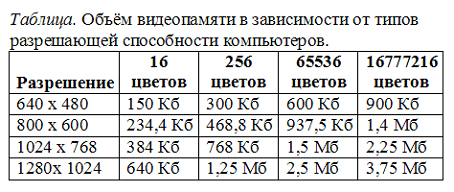
В современных компьютерах разрешающая способность
(количество точек на экране), а также количество цветов зависит от видеоадаптера и может изменяться программно.
Цветные изображения могут иметь различные режимы: 16 цветов, 256 цветов, 65536 цветов (high color
), 16777216 цветов (true color
). На одну точку для режима high color
необходимо 16 бит или 2 байта.
Наиболее распространённой разрешающей способностью экрана является разрешение 800 на 600 точек, т.е. 480000 точек. Рассчитаем необходимый для режима high color объём видеопамяти: 2 байт *480000=960000 байт.
Для измерения объёма информации используются и более крупные единицы:
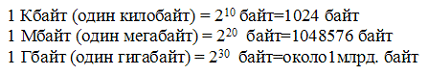
Следовательно, 960000 байт приблизительно равно 937,5 Кбайт.
Если человек говорит по восемь часов в день без перерыва, то за 70 лет жизни он наговорит около 10 гигабайт информации (это 5 миллионов страниц - стопка бумаги высотой 500 метров).
Скорость передачи информации - это количество битов, передаваемых в 1 секунду. Скорость передачи 1 бит в 1 секунду называется 1 бод.
В видеопамяти компьютера хранится битовая карта, являющаяся двоичным кодом изображения, откуда она считывается процессором (не реже 50 раз в секунду) и отображается на экран.
Двоичное кодирование звуковой информации.
С начала 90-х годов персональные компьютеры получили возможность работать со звуковой информацией. Каждый компьютер, имеющий звуковую плату, может сохранять в виде файлов (файл - это определённое количество информации, хранящееся на диске и имеющее имя
) и воспроизводить звуковую информацию. С помощью специальных программных средств (редакторов аудио файлов) открываются широкие возможности по созданию, редактированию и прослушиванию звуковых файлов. Создаются программы распознавания речи, и появляется возможность управления компьютером голосом.
Именно звуковая плата (карта) преобразует аналоговый сигнал в дискретную фонограмму и наоборот, «оцифрованный» звук – в аналоговый (непрерывный) сигнал, который поступает на вход динамика.

При двоичном кодировании аналогового звукового сигнала непрерывный сигнал дискретизируется, т.е. заменяется серией его отдельных выборок - отсчётов. Качество двоичного кодирования зависит от двух параметров: количества дискретных уровней сигнала и количества выборок в секунду. Количество выборок или частота дискретизации в аудиоадаптерах бывает различной: 11 кГц, 22 кГц, 44,1 кГц и др. Если количество уровней равно 65536, то на один звуковой сигнал рассчитано 16 бит (216). 16-разрядный аудиоадаптер точнее кодирует и воспроизводит звук, чем 8-разрядный.
Количество бит, необходимое для кодирования одного уровня звука, называется глубиной звука.
Объём моноаудиофайла (в байтах) определяется по формуле:

При стереофоническом звучании объём аудиофайла удваивается, при квадрофоническом звучании – учетверяется.
По мере усложнения программ и увеличения их функций, а также появления мультимедиа-приложений, растёт функциональный объём программ и данных. Если в середине 80-х годов обычный объём программ и данных составлял десятки и лишь иногда сотни килобайт, то в середине 90-х годов он стал составлять десятки мегабайт. Соответственно растёт объём оперативной памяти.
Учебник состоит из двух разделов: теоретического и практического. В теоретической части учебника изложены основы современной информатики как комплексной научно-технической дисциплины, включающей изучение структуры и общих свойств информации и информационных процессов, общих принципов построения вычислительных устройств, рассмотрены вопросы организации и функционирования информационно-вычислительных сетей, компьютерной безопасности, представлены ключевые понятия алгоритмизации и программирования, баз данных и СУБД. Для контроля полученных теоретических знаний предлагаются вопросы для самопроверки и тесты. Практическая часть освещает алгоритмы основных действий при работе с текстовым процессором Microsoft Word, табличным редактором Microsoft Excel, программой для создания презентаций Microsoft Power Point, программами-архиваторами и антивирусными программами. В качестве закрепления пройденного практического курса в конце каждого раздела предлагается выполнить самостоятельную работу.
Книга:
Разделы на этой странице:
В настоящее время во всех вычислительных машинах информация представляется с помощью электрических сигналов. При этом возможны две формы ее представления – в виде непрерывного сигнала (с помощью сходной величины – аналога) и в виде нескольких сигналов (с помощью набора напряжений, каждое из которых соответствует одной из цифр представляемой величины).
Первая форма представления информации называется аналоговой, или непрерывной. Величины, представленные в такой форме, могут принимать принципиально любые значения в определенном диапазоне. Количество значений, которые может принимать такая величина, бесконечно велико. Отсюда названия – непрерывная величина и непрерывная информация. Слово непрерывность отчетливо выделяет основное свойство таких величин – отсутствие разрывов, промежутков между значениями, которые может принимать данная аналоговая величина. При использовании аналоговой формы для создания вычислительной машины потребуется меньшее число устройств (каждая величина представляется одним, а не несколькими сигналами), но эти устройства будут сложнее (они должны различать значительно большее число состояний сигнала). Непрерывная форма представления используется в аналоговых вычислительных машинах (АВМ). Эти машины предназначены в основном для решения задач, описываемых системами дифференциальных уравнений: исследования поведения подвижных объектов, моделирования процессов и систем, решения задач параметрической оптимизации и оптимального управления. Устройства для обработки непрерывных сигналов обладают более высоким быстродействием, они могут интегрировать сигнал, выполнять любое его функциональное преобразование и т. п. Однако из-за сложности технической реализации устройств выполнения логических операций с непрерывными сигналами, длительного хранения таких сигналов, их точного измерения АВМ не могут эффективно решать задачи, связанные с хранением и обработкой больших объемов информации.
Вторая форма представления информации называется дискретной (цифровой). Такие величины, принимающие не все возможные, а лишь вполне определенные значения, называются дискретными (прерывистыми). В отличие от непрерывной величины, количество значений дискретной величины всегда будет конечным. Дискретная форма представления используется в цифровых электронно-вычислительных машинах (ЭВМ), которые легко решают задачи, связанные с хранением, обработкой и передачей больших объемов информации.
Для автоматизации работы ЭВМ с информацией, относящейся к различным типам, очень важно унифицировать их форму представления – для этого обычно используется прием кодирования.
Кодирование – это представление сигнала в определенной форме, удобной или пригодной для последующего использования сигнала. Говоря строже, это правило, описывающее отображение одного набора знаков в другой набор знаков. Тогда отображаемый набор знаков называется исходным алфавитом, а набор знаков, который используется для отображения, – кодовым алфавитом, или алфавитом для кодирования. При этом кодированию подлежат как отдельные символы исходного алфавита, так и их комбинации. Аналогично для построения кода используются как отдельные символы кодового алфавита, так и их комбинации.
Совокупность символов кодового алфавита, применяемых для кодирования одного символа (или одной комбинации символов) исходного алфавита, называется кодовой комбинацией, или, короче, кодом символа. При этом кодовая комбинация может содержать один символ кодового алфавита.
Символ (или комбинация символов) исходного алфавита, которому соответствует кодовая комбинация, называется исходным символом.
Совокупность кодовых комбинаций называется кодом.
Взаимосвязь символов (или комбинаций символов, если кодируются не отдельные символы исходного алфавита) исходного алфавита с их кодовыми комбинациями составляет таблицу соответствия (или таблицу кодов).
В качестве примера можно привести систему записи математических выражений, азбуку Морзе, морскую флажковую азбуку, систему Брайля для слепых и др.
В вычислительной технике также существует своя система кодирования – она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1 (используется двоичная система счисления). Эти знаки называются двоичными цифрами, или битами (binary digital).
Если увеличивать на единицу количество разрядов в системе двоичного кодирования, то увеличивается в два раза количество значений, которое может быть выражено в данной системе. Для расчета количества значений используется следующая формула:
где N – количество независимо кодируемых значений,
а m – разрядность двоичного кодирования, принятая в данной системе.
Например, какое количество значений (N) можно закодировать 10-ю разрядами (m)?
Для этого возводим 2 в 10 степень (m) и получаем N=1024, т. е. в двоичной системе кодирования 10-ю разрядами можно закодировать 1024 независимо кодируемых значения.
Кодирование текстовой информации
Для кодирования текстовых данных используются специально разработанные таблицы кодировки, основанные на сопоставлении каждого символа алфавита с определенным целым числом. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы. Но не все так просто, и существуют определенные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время, наоборот, вызваны изобилием одновременно действующих и противоречивых стандартов. Практически для всех распространенных на земном шаре языков созданы свои кодовые таблицы. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, что до сих пор пока еще не стало возможным.
Кодирование графической информации
Кодирование графической информации основано на том, что изображение состоит из мельчайших точек, образующих характерный узор, называемый растром. Каждая точка имеет свои линейные координаты и свойства (яркость), следовательно, их можно выразить с помощью целых чисел – растровое кодирование позволяет использовать двоичный код для представления графической информации. Черно-белые иллюстрации представляются в компьютере в виде комбинаций точек с 256 градациями серого цвета – для кодирования яркости любой точки достаточно восьмиразрядного двоичного числа.
Для кодирования цветных графических изображений применяется принцип декомпозиции (разложения) произвольного цвета на основные составляющие. При этом могут использоваться различные методы кодирования цветной графической информации. Например, на практике считается, что любой цвет, видимый человеческим глазом, можно получить путем механического смешивания основных цветов. В качестве таких составляющих используют три основных цвета: красный (Red, R), зеленый (Green, G) и синий (Blue, B). Такая система кодирования называется системой RGB.
На кодирование цвета одной точки цветного изображения надо затратить 24 разряда. При этом система кодирования обеспечивает однозначное определение 16,5 млн различных цветов, что на самом деле близко к чувствительности человеческого глаза. Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным (True Color).
Каждому из основных цветов можно поставить в соответствие дополнительный цвет, то есть цвет, дополняющий основной цвет до белого. Соответственно дополнительными цветами являются: голубой (Cyan, C), пурпурный (Magenta, M) и желтый (Yellow, Y). Такой метод кодирования принят в полиграфии, но в полиграфии используется еще и четвертая краска – черная (Black, K). Данная система кодирования обозначается CMYK, и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим называется полноцветным (True Color).
Если уменьшать количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но при этом диапазон кодируемых цветов заметно сокращается. Кодирование цветной графики 16-разрядными двоичными числами называется режимом High Color.
Кодирование звуковой информации
Приемы и методы кодирования звуковой информации пришли в вычислительную технику наиболее поздно и до сих пор далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, хотя можно выделить два основных направления.
Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармоничных сигналов разной частоты, каждый из которых представляет правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства – аналогово-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях часть информации теряется, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с «окрасом», характерным для электронной музыки.
Метод таблично-волнового синтеза (Wave-Table) лучше соответствует современному уровню развития техники. Имеются заранее подготовленные таблицы, в которых хранятся образцы звуков для множества различных музыкальных инструментов. В технике такие образцы называются сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения. Поскольку в качестве образцов используются «реальные» звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
Единицы измерения данных
Наименьшей единицей измерения информации является байт, равный восьми битам. Одним байтом можно закодировать одно из 256 значений. Существуют и более крупные единицы, такие как килобайт (Кбайт), мегабайт (Мбайт), гигабайт (Гбайт) и терабайт (Тбайт).
1 байт = 8 бит
1 Кбайт = 1024 байт
1 Мбайт = 1024 Кбайт = 2 20 байт
1 Гбайт = 1024 Мбайт = 2 30 байт
1 Тбайт = 1024 Гбайт = 2 40 байт
В информатике большое число информационных процессов проходит с использованием кодирования данных . Поэтому понимание данного процесса очень важно при постижении азов этой науки. Под кодированием информации понимают процесс преобразования символов записанных на разных естественных языках (русский язык, английский язык и т.д.) в цифровое обозначение.

Это означает, что при кодировании текста каждому символу присваивается определенное значение в виде нулей и единиц – .
Зачем кодировать информацию?
Во-первых, необходимо ответить на вопрос для чего кодировать информацию ? Дело в том, что компьютер способен обрабатывать и хранить только лишь один вид представления данных – цифровой. Поэтому любую входящую в него информацию необходимо переводить в цифровой вид .
Стандарты кодирования текста
Чтобы все компьютеры могли однозначно понимать тот или иной текст, необходимо использовать общепринятые стандарты кодирования текста . В прочих случаях потребуется дополнительное перекодирование или несовместимость данных.
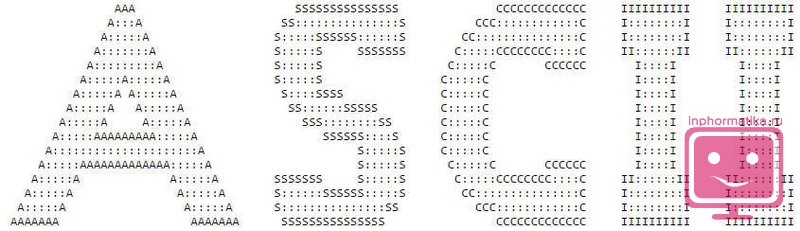
ASCII
Самым первым компьютерным стандартом кодирования символов стал ASCII (полное название - American Standart Code for Information Interchange). Для кодирования любого символа в нём использовали всего 7 бит. Как вы помните, что закодировать при помощи 7 бит можно лишь 27 символов или 128 символов. Этого достаточно, чтобы закодировать заглавные и прописные буквы латинского алфавита, арабские цифры, знаки препинания, а так же определенный набор специальных символов, к примеру, знак доллара - «$». Однако, чтобы закодировать символы алфавитов других народов (в том числе и символов русского алфавита) пришлось дополнять код до 8 бит (28=256 символов). При этом, для каждого языка использовалась свой отдельная кодировка.
UNICODE
Нужно было спасать положение в плане совместимости таблиц кодировки . Поэтому, со временем были разработаны новые обновлённые стандарты. В настоящее время наиболее популярной является кодировка под названием UNICODE . В ней каждый символ кодируется с помощью 2-х байт, что соответствует 216=62536 разным кодам.
Стандарты кодирования графических данных
Чтобы закодировать изображение требуется гораздо больше байт, чем для кодирования символов. Большинство созданных и обработанных изображений, хранящихся в памяти компьютера, разделяют на две основные группы:
- изображения растровой графики;
- изображения векторной графики.
Растровая графика
В растровой графике изображение представлено набором цветных точек. Такие точки называют пикселями (pixel). При увеличении изображения такие точки превращаются в квадратики.
Для кодирования чёрно-белого изображения каждый пиксель кодируется одним битом. К примеру, чёрный цвет - 0, а белый - 1)
Наше прошлое изображение можно закодировать так:
При кодировании нецветных изображений чаще всего применяют палитру из 256 оттенков серого, начиная от белого и заканчивая чёрным. Поэтому для кодирования такой градации достаточно одного байта (28=256).
В кодирования цветных изображений применяют несколько цветовых схем.
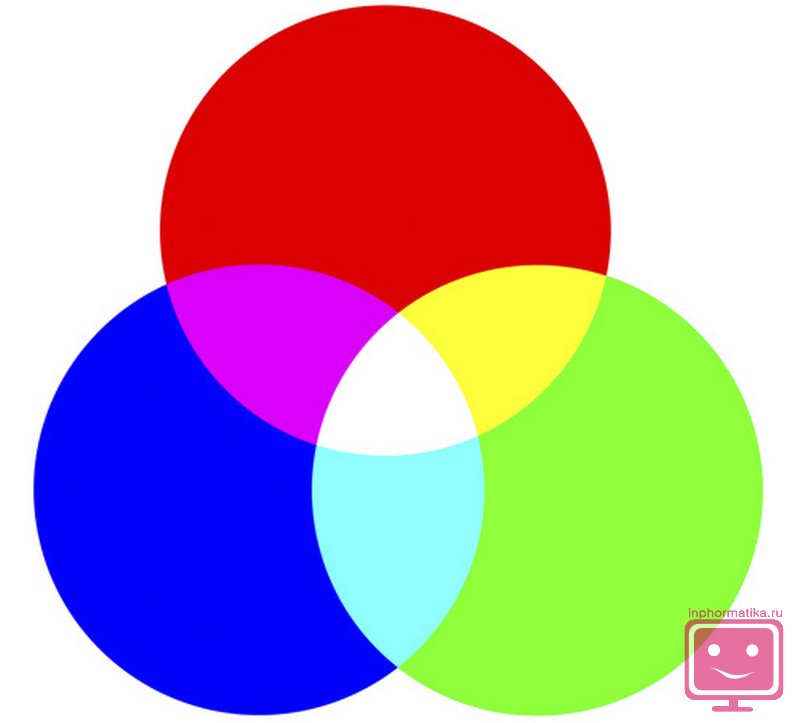
На практике, чаще применяют цветовую модель RGB , где соответственно используется три основных цвета: красный, зелёный и синий. Остальные цветовые оттенки получаются при смешивании этих основных цветов.
Таким образом, для кодирования модели из трёх цветов в 256 тонов, получается свыше 16,5 миллионов разных цветовых оттенков. То есть для кодирования применяют 3⋅8=24 бита, что соответствует 3 байтам.
Естественно, что можно использовать минимальное количество бит для кодирования цветных изображений, но тогда может быть образовано и меньшее количество цветовых тонов, в связи, с чем качество изображения существенно понизится.
Чтобы определить размер изображения нужно умножить количество пикселей в ширину на длину количество пикселей и ещё раз умножить на размер самого пикселя в байтах.
- а - количество пикселей в ширину;
- b - количество пикселей в длину;
- I – размер одного пикселя в байтах.
К примеру, цветное изображение размером 800⋅600 пикселей, занимает 60000 байт.
Векторная графика
Объекты векторной графики кодируются совершенно по-другому. Здесь изображение состоит из линий, которые могут иметь свои коэффициенты кривизны.

Стандарты кодирования звука
Звуки, которые слышит человек, представляют собой колебания воздуха. Звуковые колебания – это процесс распространения волн.
Звук имеет две основные характеристики:
- амплитуда колебаний – определяет громкость звука;
- частота колебания - определяет тональность звука.
Звук можно преобразовать в электрический сигнал, с помощью микрофона. Звук кодируется с определенным, заранее заданным интервалом времени. В этом случае измеряется размер электрического сигнала и присваивается бинарная величина. Чем чаще делают данные измерения, тем выше качество звука.

Компакт-диск объемом 700 Мб, вмещает порядка 80 минут звука CD-качества.
Стандарты кодирования видео
Как вы знаете, видеоряд состоит из быстро меняющихся фрагментов. Смена кадров происходит со скоростью в интервале 24-60 кадров в секунду.
Размер видеоряда в байтах определяется размером кадра (количеством пикселей на экран по высоте и ширине), количеством используемых цветов, а также количеством кадров в секунду. Но наряду с этим может присутствовать ещё и звуковая дорожка.
запоминающий устройство кодировка компьютер
Современный компьютер может обрабатывать числовую, текстовую, графическую, звуковую и видео информацию. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется алфавит мощностью два (всего два символа 0 и 1). Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1). Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц - машинным языком.
Каждая цифра машинного двоичного кода несет количество информации равное одному биту. Данный вывод можно сделать, рассматривая цифры машинного алфавита, как равновероятные события. При записи двоичной цифры можно реализовать выбор только одного из двух возможных состояний, а, значит, она несет количество информации равное 1 бит. Следовательно, две цифры несут информацию 2 бита, четыре разряда - 4 бита и т. д. Чтобы определить количество информации в битах, достаточно определить количество цифр в двоичном машинном коде.
Кодирование информации -- процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
> Способы кодирования
Двоичное кодирование текстовой информации
Начиная с 60-х годов, компьютеры все больше стали использовать для обработки текстовой информации и в настоящее время большая часть ПК в мире занято обработкой именно текстовой информации.
Традиционно для кодирования одного символа используется количество информации равное 1 байту (1 байт = 8 битов). Для кодирования одного символа требуется один байт информации.
Учитывая, что каждый бит принимает значение 1 или 0, получаем, что с помощью 1 байта можно закодировать 256 различных символов. (28=256)
Кодирование заключается в том, что каждому символу ставиться в соответствие уникальный двоичный код от 00000000 до 11111111 (или десятичный код от 0 до 255). Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется кодовой таблицей (например, ASCII). Обратите внимание! Цифры кодируются по стандарту ASCII в двух случаях - при вводе-выводе и когда они встречаются в тексте. Если они участвуют в вычислениях, то осуществляется их преобразование в другой двоичных код.
Возьмем число 57. При использовании в тексте каждая цифра будет представлена своим кодом в соответствии с таблицей ASCII. В двоичной системе это - 00110101 и 00110111. При использовании в вычислениях код этого числа будет получен по правилам перевода в двоичную систему и получим - 00111001.
Кодирование графической информации
Под графической информацией можно понимать рисунок, чертеж, фотографию, картинку в книге, изображения на экране телевизора или в кинозале и т. д. Для обсуждения общих принципов кодирования графической информации в качестве конкретного, достаточно общего случая графического объекта выберем изображение на экране телевизора. Это изображение состоит из некоторого количества горизонтальных линий - строк. А каждая строка в свою очередь состоит из элементарных мельчайших единиц изображения - точек, которые принято называть пикселами (picsel - PICture"S ELement - элемент картинки). Весь массив элементарных единиц изображения называют растром (лат. rastrum - грабли). Степень четкости изображения зависит от количества строк на весь экран и количества точек в строке, которые представляют разрешающую способность экрана или просто разрешение. Чем больше строк и точек, тем четче и лучше изображение. Достаточно хорошим считается разрешение 640x480, то есть 640 точек на строку и 480 строчек на экран.
Строки, из которых состоит изображение, можно просматривать сверху вниз друг за другом, как бы составив из них одну сплошную линию. После полного просмотра первой строки просматривается вторая, за ней третья, потом четвертая и т. д. до последней строки экрана. Так как каждая из строк представляет собой последовательность пикселей, то все изображение, вытянутое в линию, также можно считать линейной последовательностью элементарных точек. В рассматриваемом случае эта последовательность состоит из 640x480=307200 пикселей. Вначале рассмотрим принципы кодирования монохромного изображения, то есть изображения, состоящего из любых двух контрастных цветов - черного и белого, зеленого и белого, коричневого и белого и т. д. Для простоты обсуждения будем считать, что один из цветов - черный, а второй - белый. Тогда каждый пиксель изображения может иметь либо черный, либо белый цвет. Поставив в соответствие черному цвету двоичный код “0”, а белому - код “1” (либо наоборот), мы сможем закодировать в одном бите состояние одного пикселя монохромного изображения. А так как байт состоит из 8 бит, то на строчку, состоящую из 640 точек, потребуется 80 байтов памяти, а на все изображение - 38 400 байтов.
Однако полученное таким образом изображение будет чрезмерно контрастным. Реальное черно-белое изображение состоит не только из белого и черного цветов. В него входят множество различных промежуточных оттенков - серый, светло-серый, темно-серый и т. д. Если кроме белого и черного цветов использовать только две дополнительные градации, скажем светло-серый и темно-серый, то для того чтобы закодировать цветовое состояние одного пикселя, потребуется уже два бита. При этом кодировка может быть, например, такой: черный цвет - 002, темно-серый - 012, светло-серый - 102, белый - 112.
Общепринятым на сегодняшний день, дающим достаточно реалистичные монохромные изображения, считается кодирование состояния одного пикселя с помощью одного байта, которое позволяет передавать 256 различных оттенков серого цвета от полностью белого до полностью черного. В этом случае для передачи всего растра из 640x480 пикселей потребуется уже не 38 400, а все 307 200 байтов.
Цветное изображение может формироваться различными способами. Один из них - метод RGB (от слов Red, Green, Blue - красный, зеленый, синий), который опирается на то, что глаз человека воспринимает все цвета как сумму трех основных цветов - красного, зеленого и синего. Например, сиреневый цвет - это сумма красного и синего, желтый цвет - сумма красного и зеленого и т. д. Для получения цветного пикселя в одно и то же место экрана направляется не один, а сразу три цветных луча. Опять упрощая ситуацию, будем считать, что для кодирования каждого из цветов достаточно одного бита. Нуль в бите будет означать, что в суммарном цвете данный основной отсутствует, а единица - присутствует. Следовательно, для кодирования одного цветного пикселя потребуется 3 бита - по одному на каждый цвет. Пусть первый бит соответствует красному цвету, второй - зеленому и третий - синему. Тогда код 101(2) обозначает сиреневый цвет - красный есть, зеленого нет, синий есть, а код 110(2) - желтый цвет - красный есть, зеленый есть, синего нет. При такой схеме кодирования каждый пиксель может иметь один из восьми возможных цветов. Если же каждый из цветов кодировать с помощью одного байта, как это принято для реалистического монохромного изображения, то появится возможность передавать по 256 оттенков каждого из основных цветов. А всего в этом случае обеспечивается передача 256x256x256=16 777 216 различных цветов, что достаточно близко к реальной чувствительности человеческого глаза. Таким образом, при данной схеме кодирования цвета на изображение одного пикселя требуется 3 байта, или 24 бита, памяти. Этот способ представления цветной графики принято называть режимом True Color (true color - истинный цвет) или полноцветным режимом.
Следует упомянуть еще один часто используемый метод представления цвета, в котором вместо основного цвета используется его дополнение до белого. Если три цвета: красный, зеленый и синий вместе дают белый, то дополнением для красного, очевидно, является сочетание зеленого и синего, то есть голубой цвет. Аналогичным образом дополнением для зеленого является сочетание красного и синего, то есть пурпурный, а для синего - сочетание красного и зеленого, то есть желтый цвет. Эти три цвета - голубой, пурпурный и желтый с добавлением черного образуют основные цвета в системе кодирования, которая называется CMYK (от Cyan - голубой, Magenta - пурпурный, Yellow - желтый и blacK - черный). Этот режим также относится к полноцветным, но для передачи состояния одного пикселя в этом случае требуется 32 бита, или четыре байта, памяти, и может быть передано 4 294 967 295 различных цветов.
Полноцветные режимы требуют очень много памяти. Так, для обсуждавшегося выше растра 640x480 при использовании метода RGB требуется 921 600, а для режима CMYK - 1 228 800 байтов памяти. В целях экономии памяти разрабатываются различные режимы и графические форматы, которые немного хуже передают цвет, но требуют гораздо меньше памяти. В частности, можно упомянуть режим High Color (high color - богатый цвет), в котором для передачи цвета одного пикселя используется 16 битов и, следовательно, можно передать 65 535 цветовых оттенков, а также индексный режим, который базируется на заранее созданной таблице цветовых оттенков. Нужный цвет выбирается из этой таблицы с помощью номера - индекса, который занимает всего один байт памяти.
При записи изображения в память компьютера кроме цвета отдельных точек необходимо фиксировать много дополнительной информации - размеры рисунка, яркость точек и т. д. Конкретный способ кодирования всей требуемой при записи изображения информации образует графический формат. Форматы кодирования графической информации, основанные на передаче цвета каждого отдельного пикселя, из которого состоит изображение, относят к группе растровых или BitMap форматов (bit map - битовая карта).
Кодирование растровых изображений.
Наиболее известными растровыми форматами являются BMP, GIF и JPEG форматы. В формате BMP (от BitMaP) задается цветность всех пикселей изображения. При этом можно выбрать монохромный режим с 256 градациями или цветной с 16 256 или 16 777 216 цветами. Этот формат требует много памяти. В формате GIF (Graphics Interchange Format - графический формат обмена) используются специальные методы сжатия кода, причем поддерживается только 256 цветов. Качество изображения немного хуже, чем в формате BMP, зато код занимает в десятки раз меньше памяти. Формат JPEG (Goint Photographic Experts Group -Уединенная группа экспертов по фотографии) использует методы сжатия, приводящие к потерям некоторых деталей. Однако поддержка 16 777 216 цветов все-таки обеспечивает высокое качество изображения. По требованиям к памяти формат JPEG занимает промежуточное положение между форматами BMP и GIF.
Кодирование чисел.
Для вывода чисел на экран используется двоично-десятичное представление чисел. В упакованном формате для каждой десятичной цифры отводится по 4 двоичных разряда (полбайта), при этом знак числа кодируется в крайнем правом полубайте числа (1100 - знак и 1101 - знак).
При выполнении сложения и вычитания двоично-десятичных чисел используется упакованный формат: Цифра | Цифра | Цифра | ... Цифра | Знак. Упакованный формат используется обычно в ПК при выполнении операций сложения и вычитания двоично - десятичных чисел. В распакованном формате для каждой десятичной цифры отводится по целому байту, при этом старшие полубайты (зона) каждого байта (кроме самого младшего) в ЭВМ заполняются кодом 0011, а в младших (левых) полубайтах обычным образом кодируются десятичные цифры. Старший полубайт (зона) самого младшего (правого) байта используется для кодирования знака числа.
Структура поля распакованного формата:
Зона | Цифра | Зона | ...| Знак | Цифра
Распакованный формат используется при вводе - выводе информации, а также при выполнении операций умножения и деления двоично-десятичных чисел.
Кодирование фильмов.
Фильм представляет собой последовательность быстро сменяющих друг друга кадров, на которых изображены последовательные фазы движения. Поскольку известны принципы кодирования отдельных кадров, то закодировать фильм как последовательность таких кадров ничего не стоит. Звук записывают независимо от изображения. При демонстрации фильма важно только добиться синхронизации звука и изображения (в кино для этого используют хлопушку -- по щелчку хлопушки совмещаются звук и изображение).
Закодированный фильм несёт в себе информацию о размере кадра в пикселях и количество используемых цветов; частоте и разрешении для звука; способе записи звука (покадровый или непрерывный для всего фильма). После этого следует последовательность закодированных картинок и звуковых фрагментов.
Кодирование векторных изображений.
Векторное изображение представляет собой совокупность графических примитивов (точка, отрезок, эллипс…). Каждый примитив описывается математическими формулами. Кодирование зависти от прикладной среды.
Растровая графика обладает существенным недостатком - изображение, закодированное в одном из растровых форматов, очень плохо “переносит” увеличение или уменьшение его размеров - масштабирование. Для решения задач, в которых приходится часто выполнять эту операцию, были разработаны методы так называемой векторной графики. В векторной графике, в отличие от основанной на точке - пикселе - растровой графики, базовым объектом является линия. При этом изображение формируется из описываемых математическим, векторным способом отдельных отрезков прямых или кривых линий, а также геометрических фигур - прямоугольников, окружностей и т. д., которые могут быть из них получены. Фирма Adobe разработала специальный язык PostScript (от poster script - сценарий плакатов, объявлений, афиш), служащий для описания изображений на базе указанных методов. Этот язык является основой для нескольких векторных графических форматов. В частности, можно указать форматы PS (PostScript) и EPS, которые используются для описания как векторных, так и растровых изображений, а также разнообразных текстовых шрифтов. Изображения и тексты, записанные в этих форматах, большинством популярных программ не воспринимаются, они могут просматриваться и печататься только с помощью специализированных аппаратных и программных средств.
Кроме растровой и векторной графики существует еще и фрактальная графика, в которой формирование изображений целиком основано на математических формулах, уравнениях, описывающих те или иные фигуры, поверхности, тела. При этом само изображение в памяти компьютера фактически не хранится - оно получается как результат обработки некоторых данных. Таким способом могут быть получены даже довольно реалистичные изображения природных ландшафтов.
Двоичное кодирование звука.
Развитие способов кодирования звуковой информации, а также движущихся изображений - анимации и видеозаписей - происходило с запаздыванием относительно рассмотренных выше разновидностей информации. Заметим, что под анимацией понимается похожее на мультипликацию “оживление” изображений, но выполняемое с помощь средств компьютерной графики. Анимация представляет собой последовательность незначительно отличающихся друг от друга, полученных с помощью компьютера картинок, которые фиксируют близкие по времени состояния движения какого-либо объекта или группы объектов. Приемлемые способы хранения и воспроизведения с помощью компьютера звуковых и видеозаписей появились только в девяностых годах двадцатого века. Эти способы работы со звуком и видео получили название мультимедийных технологий. Звук представляет собой достаточно сложное непрерывное колебание воздуха. Оказывается, что такие непрерывные сигналы можно с достаточной точностью представлять в виде суммы некоторого числа простейших синусоидальных колебаний. Причем каждое слагаемое, то есть каждая синусоида, может быть точно задана некоторым набором числовых параметров - амплитуды, фазы и частоты, которые можно рассматривать как код звука в некоторый момент времени. Такой подход к записи звука называется преобразованием в цифровую форму, оцифровыванием или дискретизацией, так как непрерывный звуковой сигнал заменяется дискретным (то есть состоящим из раздельных элементов) набором значений сигнала в некоторые моменты времени. Количество отсчетов сигнала в единицу времени называется частотой дискретизации. В настоящее время при записи звука в мультимедийных технологиях применяются частоты 8, 11, 22 и 44 кГц. Так, частота дискретизации 44 килогерца означает, что одна секунда непрерывного звучания заменяется набором из сорокачетырех тысяч отдельных отсчетов сигнала. Чем выше частота дискретизации, тем лучше качество оцифрованного звука. К наиболее распространённым звуковым кодировкам относятся такие форматы, как: MP3, WAV, MPEG, AVI.











