В чем заслуга кодирования информации. Информация информационные процессы измерение информации кодирование информации. Техническая система передачи информации
Информационные процессы, кодирование и сбор информации
1. Информационные процессы
2. Кодирование информации
3. Сбор информации
1. Информационные процессы
Если обратиться в далекое прошлое, то жалобы на обилие информации обнаруживаются тысячелетия назад.
На глиняной дощечке (шумерское письмо IV тысячелетия до нашей эры) начертано: «Настали тяжелые времена. Дети перестали слушаться родителей, и каждый норовит написать книгу».
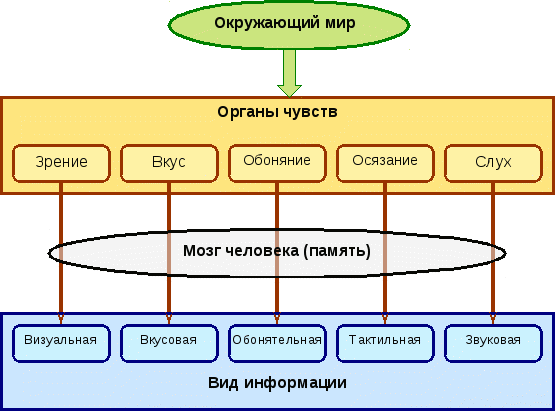
Исследования предполагают тесную связь между оперативной памятью и захватом внимания или процессом обращения к конкретной информации. Человек обращает внимание на данный стимул, сознательно или бессознательно. Этот стимул затем кодируется в рабочую память, и в этот момент память манипулирует либо для связывания ее с другой знакомой концепцией, либо с другим стимулом в текущей ситуации. Если информация считается достаточно важной для хранения на неопределенный срок, опыт будет закодирован в долгосрочную память.
А сколькостоит написать твою работу?
Если нет, он будет забыт с другой неважной информацией. Существует несколько теорий, объясняющих, как определенная информация выбрана для кодирования, в то время как другая информация отбрасывается. Ранее принятая модель фильтра предполагает, что эта фильтрация информации от сенсорной к рабочей памяти основана на конкретных физических свойствах стимулов. Для каждой частоты существует отдельный нервный путь; наше внимание выбирает, какой путь активен и может тем самым контролировать, какая информация передается в рабочую память.
Особенно модным стало жаловаться на непереносимость информационного бремени с XVII века. В XX веке заговорили ни более ни менее, как об информационной катастрофе. Информационный кризис - это возрастающее противоречие между объемом накапливаемой в обществе информации и ограниченными возможностями ее переработки отдельно взятой личностью. По оценкам специалистов в настоящее время количество информации, циркулирующей в обществе, удваивается примерно каждые 8-12 лет. Появилась уверенность в том, что для того, чтобы справиться с такой лавиной информации, недостаточно возможностей человеческого организма. Для этого нужны специальные средства и методы обработки информации, ее хранения и использования. Сформировались новые научные дисциплины - информатика, кибернетика, бионика, робототехника и др., имеющие своей целью изучение закономерностей информационных процессов, то есть процессов, цель которых - получить, передать, сохранить, обработать или использовать информацию.
Таким образом, можно следить за словами одного человека с определенной вокальной частотой, даже если в окрестностях есть много других звуков. Модель фильтра не является полностью адекватной. Теория ослабления, пересмотр модели фильтра, предполагает, что мы ослабляем информацию, которая менее актуальна, но не отфильтровывает ее полностью. Согласно этой теории информация с игнорируемыми частотами может быть проанализирована, но не так эффективно, как информация с соответствующими частотами.
Теория затухания отличается от теории позднего отбора, в которой предлагается, чтобы вся информация сначала анализировалась и оценивалась как важная или несущественная; однако эта теория менее поддерживается исследованиями. Как человек получает информацию, но также и то, что они делают с этой информацией.
В наиболее общем виде информационный процесс (ИП) определяется как совокупность последовательных действий (операций), производимых над информацией (в виде данных, сведений, фактов, идей, гипотез, теорий и пр.) для получения какого-либо результата (достижения цели).
Информация не существует сама по себе, она проявляется в информационных процессах.
Различать различные уровни обработки. Теория обработки уровней рассматривает не только то, как человек получает информацию, но и то, что человек делает с информацией после ее получения и как это влияет на общее удержание. Фергюс Крейк и Роберт Локхарт определили, что память не имеет фиксированных запасов пространства; скорее, существует несколько разных способов, которыми человек может кодировать и сохранять данные в своей памяти. Консенсус заключался в том, что информация легче переносить в долгосрочную память, когда она может быть связана с другими воспоминаниями или информацией, с которой человек знаком.
Информационные процессы всегда протекают в каких-либо системах.
Информационные процессы могут быть целенаправленными или стихийными, организованными или хаотичными, детерминированными или вероятностными, но какую бы мы ни рассматривали систему, в ней всегда присутствуют информационные процессы, и какой бы информационный процесс мы ни рассматривали, он всегда реализуется в рамках какой-либо системы - биологической, социальной, технической, социотехнической.
Существует три уровня обработки словесных данных: структурный, фонетический и семантический. Эти уровни продвигаются от самых мелких до самых глубоких. Каждый уровень позволяет человеку понимать информацию и связывать ее с прошлыми воспоминаниями, определяя, следует ли передавать информацию из краткосрочной памяти в долгосрочную память. Чем глубже обработка информации, тем легче ее получить позже.
Структурная обработка рассматривает структуру слова, например, шрифт типизированного слова или буквы внутри него. Это то, как мы оцениваем появление слов, чтобы понять их и обеспечить некоторый тип простого смысла. Письма: Обработка того, как выглядит слово, называется структурной обработкой.
«Танец» пчел - процесс передачи информации от пчел-разведчиков пчелам-сборщикам меда. Обучение в школе - это процесс передачи информации, накопленной предыдущими поколениями людей, подрастающему поколению.
Электронная почта (как совокупность соответствующих аппаратных средств и программ) предназначена для обеспечения передачи информации между компьютерами.
Структурная обработка - это самый мелкий уровень обработки: если вы видите знак для ресторана, но только занимаетесь структурной обработкой, вы можете помнить, что знак был фиолетовым с курсивным шрифтом, но на самом деле не помнил название ресторана.
Фонетическая обработка - это то, как мы слышим слово - звуки, которые он произносит, когда буквы читаются вместе. Мы сравниваем звук слова с другими словами, которые мы слышали, чтобы сохранить некоторый уровень смысла в нашей памяти. Фонетическая обработка глубже структурной обработки; то есть мы с большей вероятностью будем помнить вербальную информацию, если мы будем ее обрабатывать фонетически.
В зависимости от того, какого рода информация является предметом информационного процесса и кто является его субъектом (техническое устройство, человек, коллектив, общество в целом), можно говорить о глобальных информационных процессах, или макропроцесссах, и локальных информационных процессах, или микропроцессах.
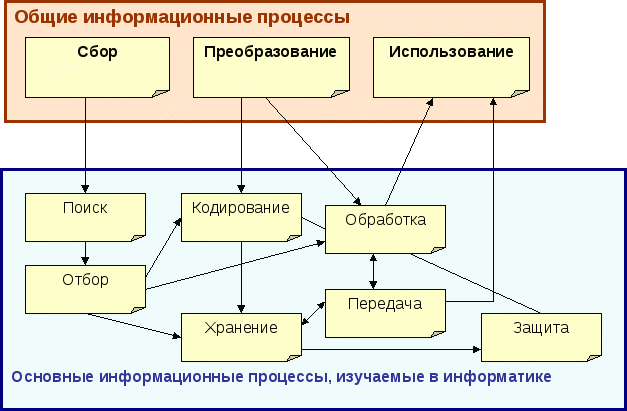
Схема взаимосвязи информационных процессов показана на рис. 1., где линиями без стрелок показаны включения одних процессов в другие (нижних на схеме в верхние), а линиями со стрелками - последовательность выполнения процессов.
Семантическая обработка - это когда мы применяем значение к словам и сравниваем или связываем ее со словами со схожими значениями. Этот более глубокий уровень обработки требует детальной репетиции, которая является более значимым способом анализа информации. Это делает более вероятным, что информация будет храниться в долгосрочной памяти, поскольку она связана с ранее изученными концепциями.
Одним из примеров использования более глубокой семантической обработки для улучшения удержания является использование метода локусов. Это когда вы связываете невизуальный материал с чем-то, что можно визуализировать. Создавая дополнительные связи между одной памятью и другой, более знакомая память работает как сигнал для новой узнаваемой информации.
Рис.1. Схема взаимосвязи информационных процессов
Процесс познания, распространение информации посредством СМИ, информационные войны, организация архивного хранения информации - глобальные ИП. Сравнение данных, двоичное кодирование текста, запись порции информации на носитель - локальные ИП.
Наиболее общими информационными процессами являются три процесса: сбор, преобразование, использование информации.
Представьте себе прогулку по знакомой местности, такой как ваша квартира. Когда вы приходите на знакомые сайты, представьте, что вы можете видеть то, что вам нужно запомнить. Предположим, вы должны помнить первых четырех президентов Соединенных Штатов: Вашингтона, Адамса, Джефферсона и Мэдисона. В вашей квартире также есть четыре комнаты: гостиная, кухня, ванная комната и спальня. Свяжите первого президента, Вашингтон, с первой комнатой. Представьте, что он стоит на вашем диване, как будто это лодка, по которой он пересек реку Делавэр.
Теперь, вторая комната - кухня, и поэтому вы представляете себе Джона Адамса. Подумайте о том, как он подходит к холодильнику, открывая и вынимая пиво и замечая, что его брат Самуэль заварил его. Память - основа обучения. Мы многое еще не знаем о природе памяти, но у нас есть некоторые идеи и модели того, как это работает. В этой главе от «Дизайн для того, как люди учатся», второе издание, Джули Дирксен смотрит, как мы обращаем внимание и кодируем информацию в память. Во-вторых, она смотрит на разные типы памяти.
Каждый из этих процессов распадается, в свою очередь, на ряд процессов, причем некоторые из последних могут входить в каждый из выделенных обобщенных процессов.
Так, сбор информации состоит из процессов поиска и отбора. В свою очередь поиск информации осуществляется в результате выполнения процедур целеполагания и использования конкретных методов поиска.
Память - это основа обучения, поэтому давайте возьмем несколько страниц, чтобы поговорить о том, как учащиеся действительно учатся и запоминают вещи. Как все эти знания попадают туда в любой день? И как мы находим и извлекаем его, когда нам это нужно?
Во-первых, мы рассмотрим, как мы обращаем внимание и кодируем информацию в память. Во-вторых, мы рассмотрим разные типы памяти. Успешное обучение включает в себя кодирование и извлечение памяти и память. Помните, что это необходимый первый шаг, но вы должны иметь возможность извлекать, манипулировать, комбинировать и вводить новшества с информацией, которую вы помните.
Методы поиска бывают «ручные» или автоматизированные. Они включают в себя такие процедуры, как формирование поискового образа (в явном или неявном виде), просмотр поступающей информации с целью сравнения её с поисковым образом.
Отбор информации производится на основе ее анализа и оценки ее свойств (объективность, достоверность, актуальность и пр.) в соответствии с выбранным критерием оценки. Отобранная информация сохраняется.
Практическая информатика – изучает программирование и использование прикладных программ
Информация в вашем мозгу не просто сидит там, как свитер шерсти в летнее время. Когда вы вводите информацию, она не пассивно ждет, чтобы ее вынимали, а вместо этого взаимодействовали с другой информацией. Таким образом, ваш мозг на самом деле не является шкафом.
Кроме того, все, что вы помещаете в свой шкаф, автоматически сохраняется в нескольких категориях, поэтому синие носки, которые вы вложили в вашу бабушку, будут одновременно поставлены с вещами, которые являются шерстью, синими, носками, нарядами, которые идут с этими носками, Бабушка, вещи, которые начинают изнашиваться, и так далее.
Хранение информации - это распространение её во времени. Хранение информации невозможно без выполнения процессов кодирования, формализации, структурирования, размещения, относящихся к общему процессу преобразования информации.
В то же время кодирование, формализацию, структурирование можно вполне обоснованно отнести к процессам обработки информации. Наряду с вышеперечисленными к процессам обработки информации относятся также информационное моделирование, вычисления по формулам (численные расчеты), обобщение, систематизация, классификация, кластеризация, схематизация и т. п.
Более того, самоорганизующийся шкаф имеет несколько перекрывающихся способов отслеживания вещей. Поэтому, когда вы убираете эти синие носки в ящике «носки», шкаф может извлекать их, глядя на «вещи, которые являются шерстяной» полкой или на вешалку «вещи, которые являются синими».
Ваш мозг - динамичный, многогранный, постоянно меняющийся объект. Все, что вы сохраните в этой книге, изменит физическую структуру вашего мозга, создав новые связи и укрепив существующие связи. Весь день мы бомбили миллионы и миллионы данных. Мы не сможем позаботиться о них, а тем более о них помним.
Обработка информации составляет основу процесса преобразования информации.
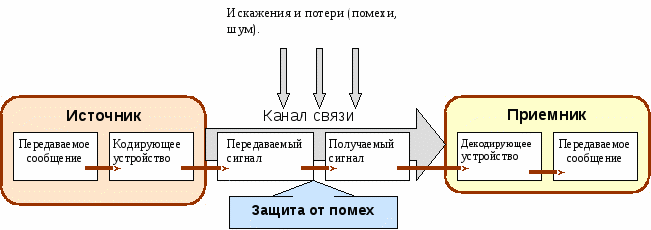
Информация может быть передана (распространена в пространстве) для её последующего использования, обработки или хранения. Процесс передачи информации включает в себя процессы кодирования, восприятия, расшифровки и пр.
Важнейшим процессом использования информации субъектом является процесс подготовки и принятия решений. Наряду с этим часто использование информации сводится к процессам формирования документированной информации (документов в том смысле, в каком этот термин используется в делопроизводстве) с целью подготовки информационного или управляющего воздействия.
К счастью, у вас есть серия фильтров и триггеров, которые позволяют вам анализировать эту информацию. Если вы решите обратить внимание на что-то, оно переходит к кратковременной памяти. Это память, которая позволяет вам держаться за идеи или мысли достаточно долго, чтобы действовать. Большинство вещей отбрасываются из кратковременной памяти, но некоторые вещи кодируются в долгосрочную память. Долгосрочная память. Это ваш шкаф, где вы храните информацию, которую вы будете хранить некоторое время.
- Сенсорная память.
- Этот тип памяти - ваш первый фильтр всего, что вы чувствуете и воспринимаете.
- Краткосрочная память.
Бухгалтер на основании имеющихся первичных документов (накладных, нарядов, табелей учета времени, инструкций по налогообложению и пр.) составляет сводную ведомость.
Сообщение о крупной аварии может стать основой для подготовки пакета документов о введении чрезвычайного положения.
В реальной практике широко используются процедуры, входящие в процесс защиты информации. Защита информации - важный компонент процессов хранения, обработки, передачи информации в системах любого типа, особенно в социальных и технических системах. К ней относятся разработка кода (шифра), кодирование (шифрование), сравнение, анализ, паролирование и т. п.
Первым уровнем памяти является сенсорная память. В основном почти все, что вы чувствуете, мгновенно держится в вашей сенсорной памяти. Большинство ощущений продолжают идти, если нет чего-то необычного или примечательного в том, что вы чувствуете. Например, остановитесь прямо сейчас и обратите внимание на все звуки, которые вы слышите. Если вы находитесь в помещении, вы, вероятно, слышите гул кондиционера или нагревательного устройства или шум от приборов или компьютеров. Если вы находитесь снаружи, в зависимости от вашего местоположения будут возникать экологические шумы.
После того, как процесс использования информации завершен, например, решение принято и субъект приступил к его реализации, как правило, возникает новая задача и необходимы новая информация либо уточнение уже имеющейся. Это приводит к тому, что субъект вновь обращается к процедуре сбора информации и пр. Поэтому, говоря об информационных процессах, следует подчеркивать не только их взаимосвязь, но и цикличность. Отсюда ясно происхождение понятий «информационный цикл», «жизненный цикл информации».
Если кто-то или что-то не привлечет ваше внимание к одному из них, вы, вероятно, не обратили внимание на эти шумы, и вы, конечно, не кодировали эти звуки в свою память. Сенсорная память не является большой проблемой для дизайнеров обучения, за исключением феномена привыкания. Привыкание означает привыкание к сенсорному стимулу до такой степени, что мы больше не замечаем и не реагируем на него.
Это позволяет вам перестать замечать раздражающий шум в холодильнике после того, как вы его некоторое время слушаете, или когда вы даже не заметите, что индикатор «проверить двигатель» светит на приборной панели, когда он был включен в течение нескольких недель.
Человек всегда стремится автоматизировать выполнение рутинных операций и операций, требующих постоянного внимания и точности. То же справедливо и по отношению к информационным процессам.
Универсальным устройством для автоматизированного выполнения информационных процессов в настоящее время является компьютер. Немалую роль в этом играют вычислительные системы и сети.
Если вещи непредсказуемы, их может быть сложнее приучить. Люди могут также приучаться к вещам, которые мы не обязательно хотим, чтобы они привыкли. Например, когда вы в последний раз уделяли большое внимание рекламе на баннере в верхней части веб-страниц? Вы, наверное, научились настраивать их. Веб-дизайнеры ссылаются на это как «слепота баннера», а исследования отслеживания глаз подтверждают, что люди не уделяют много внимания баннерной рекламе, но они часто вообще не смотрят на них.
Последствия для обучения
Согласованность может быть полезна. Согласованность может быть полезным инструментом для облегчения вашего ученика. Например, если вы используете один и тот же базовый формат для каждой главы технического руководства, ваши ученики привыкнут к формату и не должны тратить умственную энергию, постоянно ориентируясь на формат; вместо этого они могут сосредоточиться на содержании глав.
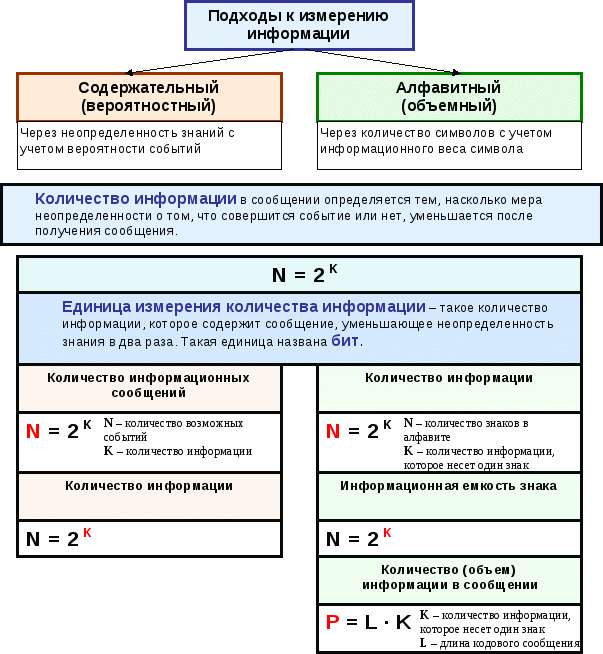
2. Кодирование информации
Информационный процесс кодирования информации встречается в нашей жизни на каждом шагу. Любое общение между людьми происходит именно благодаря тому, что они научились выражать образы, чувства и эмоции с помощью специально предназначенных для этого знаков и сигналов - звуков, жестов, букв и пр.
Одну и ту же информацию мы можем выразить разными способами.
Пример. Каким образом можно сообщить об опасности?
1. Если на вас напали, вы можете просто крикнуть «Караул!» (англичанин крикнет «Help me!»).
2. Если имеется прибор под высоким напряжением, то требуется оставить предупреждающий знак (рисунок черепа или молнии).
3. На оживленном перекрестке регулировщик помогает избежать аварии с помощью жестов.
4. Если ваш корабль тонет, то вы передадите сигнал «SOS» (... - - - ...); для этих целей на флоте могут использовать также семафорную и флажковую сигнализацию.
В каждом из этих примеров необходимо знать правило, по которому отображается информация, правило кодирования. Такое правило назовем кодом.
Код (фр. code - кодекс, свод законов). Начиная с середины XIX века это слово, помимо основного значения, означало книгу, в которой словам естественного языка сопоставлены группы цифр или букв.
Чаще всего кодирование - это процесс представления информации в виде знаков (поскольку дискретные сигналы воспринимать и обрабатывать проще, чем непрерывные).
Знак вместе с его смыслом называют символом.
Используемый для кодирования конечный набор отличных друг от друга знаков называется алфавитом.
Существует множество алфавитов.
Алфавит кириллических букв {А, Б, В, Г, Д, Е, ...};
Алфавит латинских букв {А, В, С, D, E, F, ...};
Алфавит десятичных цифр {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
Алфавит знаков зодиака {, , , , , , , , , , , }
Набор знаков азбуки Брайля для слепых;
Набор китайских идеограмм;
Математическая символика и др.;
Набор знаков генетического кода {А, Ц, Г, Т}. Важнейшие технические коды для кодирования текстов,
записанных на естественных языках, возникли с появлением электрического телеграфа, например:
Азбука Морзе;
Набор знаков второго международного телеграфного кода (телекс).
При кодировании информации для технических устройств особенно важное значение имеют наборы, состоящие всего из двух знаков: {+, -}; { , -}; {0, 1}; {да, нет}.
Алфавит, состоящий из двух знаков, называют двоичным, а каждый знак из этого алфавита - двоичным знаком.
Кодирование используется для представления информации в виде, удобном для хранения и передачи. Рассмотрим простейшие задачи кодирования и декодирования.
Пример. Попробуем закодировать числа от 0 до 100, не используя арабских или римских цифр.
Прежде всего необходимо придумать алфавит или выбрать какой-либо из известных.
Можно ли использовать в качестве «букв» алфавита знаки или гласные буквы русского алфавита?
Да, можно выбрать любой набор отличающихся друг от друга знаков.
Каждому числу, которое нужно закодировать, поставим в соответствие одну «букву» выбранного нами алфавита. Например:
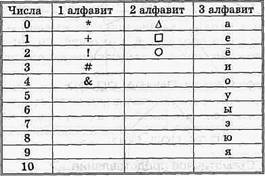
Во всех трех случаях из приведённого примера мы не решили поставленной задачи. Мы не смогли закодировать числа от 0 до 100, используя предложенные алфавиты. Получается, что наш алфавит обязательно должен состоять из 101 знака? Но с помощью всего десяти арабских цифр вы можете записать любое число. А римских цифр для кодирования первых 101 числа требуется всего пять: I, V, X, L, С.
Нужен другой подход, другое правило.
Покажем, что используя всего три символа, например , можно закодировать (зашифровать, представить) любое число. Для этого каждое число будем представлять не одним, а несколькими символами из нашего алфавита.
В нашем правиле кодирования появляется понятие «длина кода».
Длиной кода назовем количество знаков, которое используется для представления кодируемого числа (или слова).
То есть термин «код» используется в двух смыслах - как правило кодирования и как набор знаков для кодирования некоторого символа.
Количество знаков в алфавите кодирования и длина кода - совершенно разные вещи. Например, в русском алфавите 33 буквы, а слова могут быть длиной в 1, 2, 3, ... буквы.
Посмотрим, сколько чисел мы можем закодировать, если длина кода составляет не более 2 знаков.
Воспользуемся правилом, схематично представленным на рис. 2.
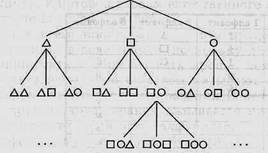
Рис. 2. Схематичное представление правила кодирования
Если посмотреть на схему, то видно, что на первое место в каждом коде ставится код предыдущего уровня, а к нему дописываются по одному все знаки алфавита в заданном алфавитном порядке. Такое правило кодирования позволяет перебрать все возможные коды и никогда не повториться.
Из таблицы (справа от рис. 2) видно, что при длине кода не более 2 знаков всего можно закодировать 12 (3 + 9) разных чисел. Чтобы закодировать числа 12, 13, ..., следует увеличить длину кода.
Рассмотрим задачу, обратную к задаче кодирования из предыдущего примера. Есть закодированная информация:. Коды вам известны. Длина кода - не более 2 знаков. Определите исходное число. Так как длина кода может быть 1 или 2, то
Могли быть закодированы три числа - 1, 2, 0;
Могли быть закодированы два числа - 1, 9;
Могли быть закодированы два числа - 8, 0.
Все три решения справедливы. Как вы думаете, почему? Есть ли способ, который приведет нас к однозначному решению поставленной задачи?
Коды переменной (непостоянной) длины в технике встречаются довольно редко. Исключением является лишь код Морзе.
Пример. Взгляните на международную азбуку Морзе:

Для отправителя приведенная таблица выглядит вполне логично, ибо буквы в ней расположены в алфавитном порядке. Но для человека, получающего сообщения, она неудобна.
В каком же порядке следует расположить знак азбуки Морзе, чтобы получив сигнал, мы могли, не теряя времени, определить, какой букве он соответствует. Представим азбуку Морзе в виде дерева:
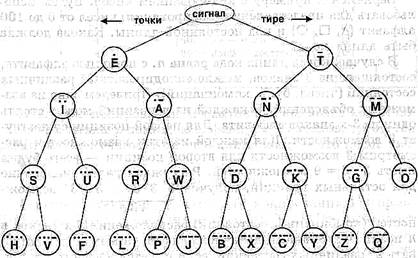
При получении сигнала - это либо точка, либо тире - записываем букву и спускаемся по дереву: если точка - влево от текущей вершины, если тире - вправо, если пауза - записываем букву текущей вершины, если длинная пауза - записываем букву и отмечаем конец слова.
По общепринятому правилу радистов продолжительность передачи точки равна продолжительности паузы, продолжительность передачи тире равна продолжительности передачи трех точек, продолжительность передачи пропуска (между буквами) равна продолжительности трех пауз.
Азбука Морзе - это пример троичного кода с набором знаков «точка», «тире», «пауза». Паузу в качестве разделителя между буквами и словами необходимо использовать, так как длина кода непостоянна.
В кодах с постоянной длиной закодированные символы могут следовать друг за другом непосредственно, без всяких разделителей. Местоположение этих символов устанавливается с помощью отсчета. И таким образом сообщение может быть раскодировано однозначно.
Наиболее простым для кодирования является двоичный алфавит. Чем меньше знаков в алфавите, тем проще должна быть устроена «машина» для распознавания (дешифровки) информационного сообщения. Однако чем меньше знаков в алфавите, тем большее их количество (большая длина кода) требуется для кодирования информации.
Вернемся к примеру с кодированием чисел. Будем использовать для представления (кодирования) чисел от 0 до 100 алфавит и код постоянной длины. Какова должна быть длина кода?
В случае, когда длина кода равна п, с помощью алфавита, состоящего из 3 знаков, можно закодировать 3 n различных состояний (чисел, букв, комбинаций). Приведем одно из возможных объяснений. В каждой из п позиций может стоять один из 3-х знаков алфавита. Для первой позиции существует 3 возможности. Для каждой из этих возможностей рассмотрим 3 возможности для второй позиции - всего будем иметь 3*3 = 9 возможностей. Рассуждая далее аналогично для остальных позиций, получим ![]() возможностей (комбинаций, состояний) расположения 3-х знаков в п позициях. Знаками двоичного алфавита можно закодировать 2 n различных состояний; если имеется алфавит, состоящий из k знаков, то можно закодировать k n различных состояний.
возможностей (комбинаций, состояний) расположения 3-х знаков в п позициях. Знаками двоичного алфавита можно закодировать 2 n различных состояний; если имеется алфавит, состоящий из k знаков, то можно закодировать k n различных состояний.
Итак, если алфавит состоит из k знаков и используется код с постоянной длиной п, то можно закодировать различных состояний.
Определим, какой длины должен быть код, чтобы, используя разные алфавиты, закодировать 10, 33, 100, 200, 1000 различных символов.
Проанализируйте таблицу:

Итак, для кодирования М различных символов кодом постоянной длины с помощью алфавита из k знаков, требуется длина кода (с учетом того, что длина кода - это целое число), равная
В вычислительной технике для кодирования информации используется двоичный алфавит {0,1}. Это позволяет использовать достаточно простые устройства для представления и автоматического распознавания (дешифровки, декодирования) программ и данных. Конструкция декодирующего устройства максимально упрощается, ведь оно должно уметь различать всего два состояния (например, 1 - есть ток в цепи, 0 - тока в цепи нет). По этой причине двоичная система и нашла такое широкое применение.
В вычислительной технике в настоящее время широко используется двоичное кодирование с алфавитом {0,1}. Наиболее распространенными кодами являются ASCII (American standard code for information interchange - американский стандартный код для обмена информацией), ДКОИ-8, Win1251.
Передача сообщений всегда осуществляется во времени. Процесс кодирования также требует определенного количества времени, которым зачастую нельзя пренебрегать. При кодировании могут ставиться определенные цели и применяться различные методы. Наиболее распространенные цели кодирования:
Экономность (уменьшение избыточности сообщения, повышение скорости передачи или обработки);
Надежность (защита от случайных искажений);
Сохранность (защита от нежелательного доступа к информации);
Удобство физической реализации (двоичное кодирование информации в ЭВМ);
Удобство восприятия (схемы, таблицы).
Одно и то же сообщение можно закодировать разными способами, то есть выразить на разных языках. В процессе развития человеческого общества люди выработали большое число языков кодирования.
К ним относятся:
Разговорные языки (русский, английский, хинди и др., всего более 2000);
Язык мимики и жестов;
Язык рисунков и чертежей;
Языки науки (языки математики, химии и т. д.);
Языки искусства (языки музыки, живописи, скульптуры);
Специальные языки (эсперанто, морской семафор, азбука Морзе, азбука Брайля для слепых и т. д.);
Среди специальных языков особо выделим языки программирования.
Программирование - кодирование информации на языке, «понятном» компьютеру.
Задачи, связанные с кодированием и декодированием сообщений, изучаются в теории кодирования - одном из разделов теории информации.
С отражаемыми объектами. Как отмечено в [А6], предпочтение аспектной концепции должно быть отдано, в частности, потому, что только она позволяет говорить об объективном существовании информации. Информация и сложные системы К определению понятия системы Рассмотренные выше аспекты, стороны понятия информации относятся либо к статической информации, рассматриваемой в определенный момент времени, ...