Таблица количество информации в сообщении. Вероятностный подход к измерению информации. Виды информационных процессов
Информация окружает нас повсюду. Мы получаем её из человеческой речи, когда слушаем радио или смотрим телевизор, читаем печатную литературу и т. д. Точно так же мы и обмениваемся ей – говорим, пишем, показываем. В этом случае единицами информации для нас можно считать буквы, цифры, звуки, знаки и т. п. Но все это составляет часть человеческого языка, понятного людям. Компьютер же оперирует другими единицами информации, понятными, соответственно, ему – битами.
Самая маленькая единица информации
Бит – это минимально возможная единица информации в цифровой системе.
Обозначается («кодируется») нулём или единицей, или точнее – «логический ноль» и «логическая единица». Почему так? Все очень просто. Компьютер - устройство, работающее при помощи электричества. Соответственно, когда на какой-то (назовём условно) линии передачи или приёма информации ток есть – это «единица» («1»), если нет – «ноль» («0»). Вот в таком виде персональный компьютер (как и другие цифровые системы) обрабатывает и обменивается информацией.
Скорость обработки и разрядность цифровых данных и устройств
Понятно, что, если мы будем обрабатывать данные не по одной линии, а сразу по нескольким, то скорость работы в этом случае резко увеличится. Поэтому, в большинстве случаев цифровые устройства оперируют не с одним битом данных, обрабатывая их последовательно друг за другом, а сразу с несколькими. В этом случае говорят о «разрядности», то есть, сколько разрядов (бит данных) за один раз может обработать цифровое устройство.
Например, если оно за один раз способно обработать 4 бита информации одновременно, то говорят, что устройство «четырехразрядное», а если восемь – то «восьмиразрядное» и т. д. Понятно, что чем больше за единицу времени информации может обработать устройство, тем оно быстрее. Таким образом, «восьмиразрядное» устройство быстрее «четырехразрядного», при условии, что скорость «взятия» данных у них одинаковая.
Разряд несёт ещё и другу функцию, определяя порядковый номер места единицы информации (бита) в передаваемых данных. Нумерация разрядов по принятому стандарту считается справа налево, и счёт ведётся с «нуля», то есть 1-й разряд данных называется «нулевым разрядом», его же принято называть «младшим» разрядом данных, а соответственно 7-й разряд – «старшим».
На сегодняшний день принята следующая терминология для определения единиц информации:
- 8 бит = 1 байт;
- 1024 байта = 1 килобайт;
- 1024 Килобайта = 1 Мегабайт;
- 1024 Мегабайта = 1 Гигабайт;
- 1024 Гигабайта = 1 Терабайт.
Скорость передачи данных
Как известно, цифровые устройства не только обрабатывают данные, но также, передают и принимают их через линии связи. В этом случае говорят о скорости передачи информации. Для того, чтобы оценить этот параметр за единицу скорости цифровых данных принимают величину равную одному биту в секунду – «1 Бит/сек».
В старые времена, для сокращения обозначения был введён термин «1 Бод», равный скорости передачи данных в 1 Бит/сек. Также, применяются и величины кратные байту: 1 Килобайт/сек. (1 КБайт/сек.), 1 Мегабайт/сек. (1 МБайт/сек.) и т. д.
Исторически сложилось, что для измерения скорости принято применять не байтовые величины, а битовые! То есть, всегда следует обращать внимание на точную запись этого параметра, например, 100 Килобит/сек и 100 Килобайт/сек – это совершенно разная скорость. В первом случае, данные передавались со скорость 100 000 бит в секунду, а во втором – 800 000 бит в секунду, так как выше уже было сказано, что 1 байт = 8 битам. Это следует чётко понимать, чтобы не путаться в данной терминологии. Например, информация размером в 1 килобайт (т. е. 1024 байта или 1024*8 = 8192 бита) будет передаваться при скорости в линии связи 1 килобит/сек – 8192: 1024 = 8 секунд. Те же самые данные мы получим при скорости в 1 килобайт/сек за 1 секунду. То есть во втором случае скорость передачи данных в 8 раз быстрее.
На сегодняшний день, благодаря внедрению новых линий связи работающих на основе оптоэлектронных технологий , скорость передачи информации возросла в сто и больше раз и составляет: от 1–2 Мбит/сек, до 1 Гбит/сек. для индивидуальных подключений не только в офисе, но уже и дома.
Размер файла
Создайте в Блокноте новый документ, введите в него одну букву «Я» и сохраните документ в папке Мои документы под именем . Откройте папку Мои документы , найдите файл , щёлкните на нём правой кнопкой мыши и выберите в открывшемся контекстном меню команду Свойства . Откроется диалоговое окно Свойства: Буква Я.txt .
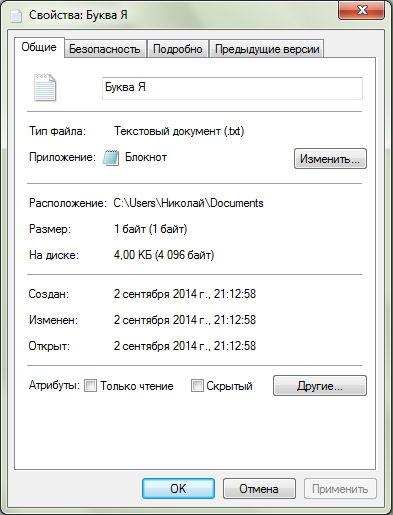
В этом окне вы увидите, что размер файла равен одному байту. Значит, для хранения одного символа требуется один байт. Заметим, что реально занимаемый файлом объем на диске обычно больше размера документа, т. к. под хранение документов место выделяется не точно равное размеру документа, а объёмами, кратными размеру кластера.
Кластер - минимальный, объём дискового пространства, который может быть выделен для размещения файла. Все файловые системы, используемые Windows для работы с жёсткими дисками , основаны на кластерах, которые состоят из одного или нескольких смежных секторов (512 байт). Чем меньше размер кластера, тем более эффективно используется дисковая память. Размер кластера определяется, как правило, автоматически при форматировании винчестера в зависимости от ёмкости диска и составляет от 512 байт до 64 Кб.
За единицу измерения количества информации принимается такое количество информации, которое содержится в сообщении, уменьшающем неопределенность знания в 2 раза. Такая единица называется битом.
Минимальной единицей измерения количества информации является бит, а следующей по величине единицей – байт, причем
1 байт = 8 битов
В международной системе СИ используют десятичные приставки «Кило» (103), «Мега» (106), «Гига» (109),… В компьютере информация кодируется с помощью двоичной знаковой системы, поэтому в кратных единицах измерения количества информации используется коэффициент 2n.
1 килобайт (Кбайт) = 210 байт = 1024 байт
1 мегабайт (Мбайт) = 210 Кбайт = 1024 Кбайт
1 гигабайт (Гбайт) = 210 Мбайт = 1024 Мбайт
1 терабайт (Тбайт) = 210 Гбайт = 1024 Гбайт
Терабайт – очень крупная единица измерения информации, поэтому применяется крайне редко. Всю информацию, которое накопило человечество, оценивают в десятки терабайт.
Двоичное кодирование текстовой информации Начиная с конца 60-х годов компьютеры все больше стали использоваться для обработки текстовой информации, и в настоящее время большая часть персональных компьютеров в мире значительную часть времени занято обработкой именно ТЕКСТОВОЙ информации.
Для представления текстовой информации обычно используется 256 различных символов (прописные и заглавные буквы русского и латинского алфавита, цифры, знаки, графические символы и т. д.). Поставим вопрос: «Какое количество бит информации или двоичных разрядов необходимо, чтобы закодировать 256 различных символов?»
256 различных символов можно рассматривать как 256 различных состояний (событий). В соответствии с вероятностным подходом к измерению количества информации необходимое количество информации для двоичного кодирования 256 символов равно;
I = log2 256 = 8 бит = 1 байт
Следовательно, для двоичного кодирования 1 символа необходим 1 байт информации или 8 двоичных разрядов. Таким образом, каждому символу соответствует своя уникальная последовательность из восьми нулей и единиц.
Присвоение символу конкретного двоичного кода - это вопрос соглашения, которое фиксируется в кодовой таблице. К сожалению, существуют пять различных кодировок русских букв, поэтому тексты - созданные в одной кодировке, не будут правильно отображаться в другой.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией, 8-битный»). Эта кодировка применяется на компьютерах с операционной системой UNIX.
Наиболее распространенная кодировка - это стандартная кириллическая кодировка Microsoft Windows, обозначаемая сокращением СР1251 («СР» означает «Code Page», «кодовая страница»). Все Windows-приложения, работающие с русским языком, поддерживают эту кодировку.
28 = 256 символов.
Для работы в среде операционной системы MS DOS используется «альтернативная» кодировка, в терминологии фирмы Microsoft - кодировка CP866.
Фирма Apple разработала для компьютеров Macintosh свою собственную кодировку русских букв (Мае).
Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наконец, появился новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, и потому с его помощью можно закодировать не 256 символов, а целых 65 536. Эту кодировку поддерживает пакет Microsoft Office 97-2003.
Двоичное кодирование текста происходит следу ющим образом: при нажатии на определенную клавишу в компьютер передается определенная последовательность электрических импульсов, причем каждому символу соответствует своя последовательность электрических импульсов (нулей и единиц на машинном языке). Программа драйвер клавиатуры и экрана по кодовой таблице определяет символ и создает его изображение на экране.
Таким образом, тексты хранятся в памяти компьютера в двоичном коде и программным способом преобразуются в изображения на экране.
Двоичное кодирование графической информации
С 80-х годов бурно развивается технология обработки на компьютере ГРАФИЧЕСКОЙ информации. Компьютерная графика широко используется в компьютерном моделировании в научных исследованиях, компьютерных тренажерах, компьютерной анимации, деловой графике, играх и т. д.
В последние годы, в связи с резким ростом аппаратных возможностей персональных компьютеров, пользователи получили возможность обрабатывать ВИДЕО информацию.
Графическая информация на экране дис плея представляется в виде изображения. Которое формируется из точек (пикселей). В современных компьютерах разрешающая способность (количество точек на экране дисплея), а также количество цветов зависит от видеоадаптера и может меняться программно.
Цветные изображения могут иметь различные режимы: 16 цветов, 256 цветов, 65 536 цветов (high color), 16 777 216 цветов (true color). Каждый цвет представляет собой одно из вероятных состояний точки экрана. Рассчитаем количество бит на точку, необходимых для режима true color: I = logs 65 536-16 бит = 2 байт.
Наиболее распространенной разрешающей способностью экрана является разрешение 800 на 600 точек, т.е. 480000 точек. Рассчитаем необходимый для режима true color объем видеопамяти: 1 = 2 байт 480 000 = 960 000 байт = 937,5 Кб. Аналогично рассчитывается объем видеопамяти, необходимый для хранения битовой карты изображений при других видеорежимах.
Разрешение
256 цветов
65536 цветов
16 777 216 цветов
В видеопамяти памяти компьютера хранится битовая карта, являющаяся двоичным кодом изображения, отсюда она считывается процессором (не реже 50 раз в секунду) и отображается на экран. Двоичное кодирование звуковой информации. Сначала 90-х годов персональные компьютеры получили возможность работать со ЗВУКОВОЙ информацией. Каждый компьютер, имеющий звуковую плату, может сохранять в виде файлов и воспроизводить звуковую информацию. С помощью специальных программных средств (редакторов аудиофайлов) открываются широкие возможности по созданию, редактированию и прослушиванию звуковых файлов. Создаются программы распознавания речи, и появляется возможность управления компьютером голосом.
При двоичном кодировании аналогового звукового сигнала непрерывный сигнал дискретизируется, т. е. заменяется серией его отдельных выборок - отсчетов. Качество двоичного кодирования зависит от двух параметров: количества распознаваемых дискретных уровней сигнала и количества выборок в секунду.
Различные звуковые карты могут обеспечить 8-или 16-битные выборки.
Замена непрерывного звукового сигнала его дискретным представлением в виде ступенек
8-битные карты позволяют закодировать 256 различных уровней дискретизации звукового сигнала, соответственно 16-битные - 65 536 уровней.
Частота дискретизации аналогового звукового сигнала (количество выборок в секунду) может принимать следующие значения: 5,5 КГц, 11 КГц, 22 КГц и 44 КГц. Таким образом, качество звука в дискретной форме может быть очень плохим (качество радиотрансляции) при 8 битах и 5,5 КГц и очень высоким (качество аудиоCD) при 16 битах и 44 КГц.
Можно оценить объем моноаудиофайла длительностью звучания 1 сек при среднем качестве звука (16 бит, 22 КГц). Это означает, что 16 бит на одну выборку необходимо умножить на 22 000 выборок в секунду, получим 43 Кб.
Наш высокотехнологичный век отличается своими широкими возможностями. С развитием электронных вычислительных машин перед людьми открылись удивительные горизонты. Любую интересующую новость теперь можно найти в глобальной сети совершенно бесплатно, не выходя из дома. Это прорыв в сфере техники. Но как же столько данных может храниться в памяти компьютера, обрабатываться и передаваться на далекие расстояния? Какие единицы измерения информации в информатике существуют? И как с ними работать? Сейчас не только люди, непосредственно занимающиеся написанием компьютерных программ, но и обычные школьники должны знать ответы на эти вопросы. Ведь это основа всего.
в компьютерной науке
Мы привыкли считать, что информация - это все те знания, которые доносят до нас. Но в информатике и компьютерных науках это слово имеет немного другое определение. Это базовая составляющая всей науки об электронных вычислительных машинах. Почему базовая, или фундаментальная? Потому что компьютерная техника обрабатывает данные, сохраняет и доносит до людей. Минимальная единица измерения информации исчисляется в битах. Сведения хранятся в компьютере до тех пор, пока юзер не захочет просмотреть их.

Мы привыкли думать, что информация - единица языка. Да, это так, но в информатике используется другое определение. Это сведения о состоянии, свойствах и параметрах объектов окружающей нас среды. Совершенно ясно, что чем больше мы узнаем сведений об объекте или явлении, тем больше понимаем, что наше представление о них мизерное. Но теперь благодаря такому огромному объему совершенно бесплатных и доступных со всех точек планеты материалов стало гораздо проще обучаться, заводить новые знакомства, работать, отдыхать и просто расслабляться за чтением книг или просмотром кинофильмов.
Алфавитный аспект измерения объема информации
Печатая документы для работы, статьи на сайты и ведя свой личный блог в интернете, мы не задумываемся о том, как проходит обмен данными между пользователем и самой вычислительной машиной. Как машина способна понимать команды, в каком виде хранит все файлы? В информатике за единицу измерения информации принят бит, который может хранить из ноликов и единиц. Суть алфавитного подхода в измерении текстовых символов заключается в последовательности знаков. Но не стоит переплетать алфавитный подход с содержанием текста. Это совершенно разные вещи. Объем таких данных пропорционален количеству введенных символов. Благодаря этому получается, что информационный вес знака из бинарного алфавита равен одному биту. Единицы измерения информации в информатике существуют разные, как и любые другие меры. Бит - это минимальная величина измерения.
Содержательный аспект высчитывания объема информации
Измерение информации базируется на основе теории вероятности. В данном случае рассматривается вопрос о том, какое количество данных содержится в получаемом человеком сообщении. Тут в ход идут теоремы дискретной математики. Для расчета материалов берутся две разные формулы в зависимости от вероятности события. При этом остаются прежними единицы измерения информации в информатике. Задачи расчета количества символов, графики по содержательному подходу гораздо сложнее, чем по алфавитному.
Виды информационных процессов

Существуют основные три типа процессов, осуществляемых в электронной вычислительной машине:
- Как проходит данный процесс? Через инструменты ввода данных, будь то клавиатура, оптическая мышь, принтер или другие получает сведения. Затем конвертирует их в бинарный код и записывает на жесткий диск в битах, байтах, мегабайтах. Для перевода любой единицы измерения информации в информатике существует таблица, по которой можно высчитать, сколько в одном мегабайте бит, и осуществить другие переводы. Компьютер все делает автоматически.
- Хранение файлов и данных в памяти устройства. Компьютер способен запоминать все в бинарном виде. Двоичный код состоит из нулей и единиц.
- Еще один из основных процессов, происходящих в электронной вычислительной машине, - передача данных. Она тоже осуществляется в бинарном виде. Но на экран монитора информация выводится уже в символьном или другом привычном для нашего восприятия виде.
Кодирование информации и мера ее измерения
За единицу измерения информации принят бит, с которым достаточно легко работать, ведь он может вмещать значение 0 или 1. Как компьютер осуществляет кодирование обычных десятичных чисел в двоичный код? Рассмотрим небольшой пример, который объяснит принцип кодирования информации компьютерной техникой.

Допустим, у нас есть число в привычной системе исчисления - 233 . Чтобы перевести его в бинарный вид, необходимо делить на 2 до того момента, пока оно не станет меньше самого делителя (в нашем случае - 2).
- Начинаем деление: 233/2=116. Остаток записываем отдельно, это и будут составляющие ответного бинарного кода. В нашем случае это 1.
- Вторым действием будет такое: 116/2=58. Остаток от деления - 0 - опять записываем отдельно.
- 58/2=29 без остатка. Не забываем записывать оставшийся 0, ведь, утеряв всего один элемент, вы получите уже совершенно другую величину. Этот код далее будет храниться на винчестере компьютера и являть собой биты - минимальные единицы измерения информации в информатике. 8-классники уже способны справиться с переводом чисел из десятичного типа исчисления в двоичный, и наоборот.
- 29/2=14 с остатком 1. Его и записываем отдельно к уже полученным двоичным цифрам.
- 14/2=7. Остаток от деления равен 0.
- Еще немного, и бинарный код будет готов. 7/2=3 с остатком 1, который и записываем в будущий ответ двоичного кода.
- 3/2=1 с остатком 1. Отсюда записываем в ответ две единицы. Одну - как остаток, другую - как последнее оставшееся число, которое уже не делится на 2.
Необходимо запомнить, что ответ записывается в обратном порядке. Первое получившееся бинарное число из первого действия будет последней цифрой, из второго - предпоследней, и так далее. Наш итоговый ответ - 11101001 .

Такое бинарное число записывается в памяти компьютера и хранится в этом виде до тех пор, пока пользователь не захочет посмотреть на него с экрана монитора. Бит, байт, мегабайт, гигабайт - единицы измерения информации в информатике. Именно в таких величинах и хранятся бинарные данные в компьютере.
Обратный перевод числа из бинарной в десятичную систему
Для того чтобы осуществить обратный перевод из бинарной величины в десятичную систему исчисления, необходимо воспользоваться формулой. Считаем количество знаков в двоичной величине, начиная с 0. В нашем случае их 8, но если начинать отсчет с нуля, тогда они заканчиваются порядковым номером 7. Теперь необходимо каждую цифру из кода умножить на 2 в степени 7, 6, 5,…, 0.
1*2 7 +1*2 6 +1*2 5 +0*2 4 +1*2 3 +0*2 2 +0*2 1 +1*2 0 =233. Вот и наше начальное число, которое было взято еще до перевода в бинарный код.

Теперь вам известна суть компьютерным устройством и минимальная мера хранения информации.
Минимальная единица измерения информации: описание
Как уже упоминалось выше, наименьшей величиной измерения информации считается бит. Это слово английского происхождения, в переводе оно означает "двоичная цифра". Если посмотреть на данную величину с другой стороны, то можно сказать, что это ячейка памяти в электронных вычислительных машинах, которая хранится в виде 0 либо 1. Биты можно перевести в байты, мегабайты и еще большие величины информации. Электронная вычислительная машина сама занимается такой процедурой, когда сохраняет бинарный код в ячейки памяти винчестера.

Некоторые пользователи компьютера могут захотеть вручную и быстро перевести меры объема цифровой информации из одной в другую. Для таких целей были разработаны онлайн-калькуляторы, они сию же секунду осуществят операцию, на которую вручную можно было бы потратить много времени.
Единицы измерения информации в информатике: таблица величин
Компьютеры, флеш-накопители и другие устройства запоминания и обработки информации отличаются между собой объемом памяти, который обычно исчисляется в гигабайтах. Необходимо посмотреть на основную таблицу величин, чтобы увидеть сопоставимость одной единицы измерения информации в информатике в порядке возрастания со второй.
Использование максимальной единицы измерения информации
В наше время максимальную меру объема информации, которая называется йоттабайтом, планируют использовать в агентстве национальной безопасности в целях хранения всех аудио- и видеоматериалов, полученных из общественных мест, где установлены видеокамеры и микрофоны. На данный момент йоттабайты - наибольшие единицы измерения информации в информатике. Это предел? Вряд ли кто-то сможет дать сейчас точный ответ.
Мы постоянно что-то измеряем — время, длину, скорость, массу. И для каждой величины есть своя единица измерения, а зачастую несколько. Метры и километры, килограммы и тонны, секунды и часы — все это нам знакомо. А как же измерить информацию? Для информации тоже придумали единицу измерения и назвали ее бит .
Бит — это минимальная единица измерения информации.
В одном бите содержится очень мало информации. Он может принимать только одно из двух значений (1 или 0, да или нет, истина или ложь). Измерять информацию в битах очень неудобно — числа получаются огромные. Ведь не измеряют же массу автомобиля в граммах.
Например, если представить объем флешки в 4Гб в битах мы получим 34 359 738 368 бит. Представьте, пришли вы в компьютерный магазин и просите продавца дать вам флешку объемом 34 359 738 368 бит. Вряд ли он вас поймет
Поэтому в информатике и в жизни используются производные от бита единицы измерения информации. Но у них у всех есть замечательное свойство — они являются степенями двойки с шагом 10.
Итак, возьмем число 2 и возведем его в нулевую степень. Получим 1 (любое число в нулевой степени равно 1). Это будет байт.
В одном байте 8 бит.
Теперь возведем 2 в 10-ю степень — получим 1024. Это килобайт (Кбайт).
В одном килобайте 1024 байт.
Если возвести 2 в 20 степень — получим мегабайт (Мбайт).
1Мбайт = 1024 Кбайт.
| Название | Символ | Степень |
|---|---|---|
| байт | Б | 2 0 |
| килобайт | кБ | 2 10 |
| мегабайт | МБ | 2 20 |
| гигабайт | ГБ | 2 30 |
| терабайт | ТБ | 2 40 |
| петабайт | ПБ | 2 50 |
| эксабайт | ЭБ | 2 60 |
| зеттабайт | ЗБ | 2 70 |
| йоттабайт | ЙБ | 2 80 |
Понимание данной темы позволит успешно и к
1. Для информации существуют свои единицы измерения информации. Если рассматривать сообщения информации как последовательность знаков, то их можно представлять битами, а измерять в байтах, килобайтах, мегабайтах, гигабайтах, терабайтах и петабайтах.
Единицей измерения количества информации является бит – это наименьшая (элементарная) единица.
1бит – это количество информации, содержащейся в сообщении, которое вдвое уменьшает неопределенность знаний о чем-либо.
Байт – основная единица измерения количества информации .
Байтом называется последовательность из 8 битов.
Байт – довольно мелкая единица измерения информации. Например, 1 символ – это 1 байт.
Производные единицы измерения количества информации
1 байт=8 битов
1 килобайт (Кб)=1024 байта =210 байтов
1 мегабайт (Мб)=1024 килобайта =210 килобайтов=220 байтов
1 гигабайт (Гб)=1024 мегабайта =210 мегабайтов=230 байтов
1 терабайт (Гб)=1024 гигабайта =210 гигабайтов=240 байтов
Запомните, приставка КИЛО в информатике – это не 1000, а 1024
Методы измерения количества информации
Итак, количество информации в 1 бит вдвое уменьшает неопределенность знаний. Связь же между количеством возможных событий N и количеством информации I определяется формулой Хартли:
Алфавитный подход к измерению количества информации
При этом подходе отвлекаются от содержания (смысла) информации и рассматривают ее как последовательность знаков определенной знаковой системы. Набор символов языка, т.е. его алфавит можно рассматривать как различные возможные события. Тогда, если считать, что появление символов в сообщении равновероятно, по формуле Хартли можно рассчитать, какое количество информации несет в себе каждый символ:
Вероятностный подход к измерению количества информации
Этот подход применяют, когда возможные события имеют различные вероятности реализации. В этом случае количество информации определяют по формуле Шеннона: , где I – количество информации, N – количество возможных событий,
Pi – вероятность i-го события.
Единицы измерения информации служат для измерения объёма информации - величины, исчисляемой логарифмически. Это означает, что когда несколько объектов рассматриваются как один, количество возможных состояний перемножается, а количество информации - складывается. Не важно, идёт речь о случайных величинах в математике, регистрах цифровой памяти в технике или в квантовых системах в физике.
Чаще всего измерение информации касается объёма компьютерной памяти и объёма данных, передаваемых по цифровым каналам связи.
Первичные единицы
Сравнение разных единиц измерения информации. Дискретные величины представлены прямоугольниками, единица «нат» - горизонтальным уровнем. Чёрточки слева - логарифмы натуральных чисел.
Объём информации можно представлять как логарифм количества возможных состояний.
Наименьшее целое число, логарифм которого положителен - это 2. Соответствующая ему единица - бит - является основой исчисления информации в цифровой технике.
Единица, соответствующая числу 3 (трит) равна log23≈1,585 бита, числу 10 (хартли) - log210≈3.322 бита.
Такая единица как нат (nat), соответствующая натуральному логарифму применяется в инженерных и научных расчётах. В вычислительной технике она практически не применяется, так как основание натуральных логарифмов не является целым числом.
В проводной технике связи (телеграф и телефон) и радио исторически впервые единица информации получила обозначение бод.
Единицы, производные от бита
Целые количества бит отвечают количеству состояний, равному степеням двойки.
Особое название имеет 4 бита - ниббл (полубайт, тетрада, четыре двоичных разряда), которые вмещают в себя количество информации, содержащейся в одной шестнадцатеричной цифре.
Следующей по порядку популярной единицей информации является 8 бит, или байт (о терминологических тонкостях написано ниже). Именно к байту (а не к биту) непосредственно приводятся все большие объёмы информации, исчисляемые в компьютерных технологиях.
Такие величины как машинное слово и т. п., составляющие несколько байт, в качестве единиц измерения почти никогда не используются.
Килобайт
Для измерения больших количеств байтов служат единицы «килобайт» = байт и «Кбайт» (кибибайт, kibibyte) = 1024 байт (о путанице десятичных и двоичных единиц и терминов см. ниже). Такой порядок величин имеют, например:
Сектор диска обычно равен 512 байтам то есть половине килобайта, хотя для некоторых устройств может быть равен одному или двум кибибайт.
Классический размер «блока» в файловых системах UNIX равен одному Кбайт (1024 байт).
«Страница памяти» в процессорах x86 (начиная с модели Intel 80386) имеет размер 4096 байт, то есть 4 Кбайт.
Объём информации, получаемой при считывании дискеты «3,5″ высокой плотности» равен 1440 Кбайт (ровно); другие форматы также исчисляются целым числом Кбайт.
[править]
Мегабайт
Основная статья: Мегабайт
Единицы «мегабайт» = 1000 килобайт = байт и «мебибайт» (mebibyte) = 1024 Кбайт = 1 048 576 байт применяются для измерения объёмов носителей информации.
Объём адресного пространства процессора Intel 8086 был равен 1 Мбайт.
Оперативную память и ёмкость CD-ROM меряют двоичными единицами (мебибайтами, хотя их так обычно не называют), но для объёма НЖМД десятичные мегабайты были более популярны.
Современные жёсткие диски имеют объёмы, выражаемые в этих единицах минимум шестизначными числами, поэтому для них применяются гигабайты.
Гигабайт
Единицы «гигабайт» = 1024 мегабайт = килобайт = байт и «Гбайт» (гибибайт, gibibyte) = 1024 Мбайт = 230 байт измеряют объём больших носителей информации, например жёстких дисков. Разница между двоичной и десятичной единицами уже превышает 7 %.
Размер 32-битного адресного пространства равен 4 Гбайт ≈ 4,295 Мбайт. Такой же порядок имеют размер DVD-ROM и современных носителей на флеш-памяти. Размеры жёстких дисков уже достигают сотен и тысяч гигабайт.
Для исчисления ещё больших объёмов информации имеются единицы терабайт и тебибайт (1012 и 240 байт соответственно), петабайт и пебибайт (1015 и 250 байт соответственно) и т. д.
Что такое «байт»?
В принципе, байт определяется для конкретного компьютера как минимальный шаг адресации памяти, который на старых машинах не обязательно был равен 8 битам (а память не обязательно состоит из битов - см., например: троичный компьютер). В современной традиции, байт часто считают равным восьми битам.
В таких обозначениях как байт (русское) или B (английское) под байт (B) подразумевается именно 8 бит, хотя сам термин «байт» не вполне корректен с точки зрения теории.
Во французском языке используются обозначения o, Ko, Mo и т. д. (от слова octet) дабы подчеркнуть, что речь идёт именно о 8 битах.
Чему равно «кило»?
Основная статья: Двоичные приставки
Долгое время разнице между множителями 1000 и 1024 старались не придавать большого значения. Во избежание недоразумений следует чётко понимать различие между:
двоичными кратными единицами, обозначаемыми согласно ГОСТ 8.417-2002 как «Кбайт», «Мбайт», «Гбайт» и т. д. (два в степенях кратных десяти);
единицами килобайт, мегабайт, гигабайт и т. д., понимаемыми как научные термины (десять в степенях, кратных трём),
эти единицы по определению равны, соответственно, 103, 106, 109 байтам и т. д.
В качестве терминов для «Кбайт», «Мбайт», «Гбайт» и т. д. МЭК предлагает «кибибайт», «мебибайт», «гибибайт» и т. д., однако эти термины критикуются за непроизносимость и не встречаются в устной речи.
В различных областях информатики предпочтения в употреблении десятичных и двоичных единиц тоже различны. Причём, хотя со времени стандартизации терминологии и обозначений прошло уже несколько лет, далеко не везде стремятся прояснить точное значение используемых единиц.
В английском языке для «киби»=1024 иногда используют прописную букву K, дабы подчеркнуть отличие от обозначаемой строчной буквой приставки СИ кило. Однако, такое обозначение не опирается на авторитетный стандарт, в отличие от российского ГОСТа касательно «Кбайт».
2. С точки зрения программиста, данные - это часть программы, совокупность значений определённых ячеек памяти, преобразование которых осуществляет код. С точки зрения компилятора, процессора, операционной системы, это совокупность ячеек памяти, обладающих определёнными свойствами (возможность чтения и записи (необяз.), невозможность исполнения).
Контроль за доступом к данным в современных компьютерах осуществляется аппаратно.
В соответствии с принципом фон Неймана, одна и та же область памяти может выступать как в качестве данных, так и в качестве исполнимого кода.
Типы данных
Традиционно выделяют два типа данных - двоичные (бинарные) и текстовые.
Двоичные данные обрабатываются только специализированным программным обеспечением, знающим их структуру, все остальные программы передают данные без изменений.
Текстовые данные воспринимаются передающими системами как текст, записанный на каком-либо языке. Для них может осуществляться перекодировка (из кодировки отправляющей системы в кодировку принимающей), заменяться символы переноса строки, изменяться максимальная длина строки, изменяться количество пробелов в тексте.
Передача текстовых данных как бинарных приводит к необходимости изменять кодировку в прикладном программном обеспечении (это умеет большинство прикладного ПО, отображающего текст, получаемый из разных источников), передача бинарных данных как текстовых может привести к их необратимому повреждению.
Данные в объектно-ориентированном программировании
Могут обрабатываться функциями объекта, которому принадлежат сами, либо функциями других объектов, имеющими для этого возможность.
Данные в языках разметки
Имеют различное отображение в зависимости от выбранного способа представления.
Данные в XML
В теории множеств
В отличие от операций над элементами множества, представляют собой множество (название и элементы множества)
Операции с данными
Для повышения качества данные преобразуются из одного вида в другой с помощью методов обработки. Обработка данных включает операции:
1) ввод (сбор) данных - накопление данных с целью обеспечения достаточной полноты для принятия решений;
2) формализация данных - приведение данных, поступающих из разных источников, к одинаковой форме, для повышения их доступности;
3) фильтрация данных - это отсеивание «лишних» данных, в которых нет необходимости для повышения достоверности и адекватности;
4) сортировка данных - это упорядочивание данных по заданному признаку с целью удобства их использования;
5) архивация - это организация хранения данных в удобной и легкодоступной форме;
6) защита данных - включает меры, направленные на предотвращение утраты, воспроизведения и модификации данных;
7) транспортировка данных - приём и передача данных между участниками информационного процесса;
8) преобразование данных - это перевод данных из одной формы в другую или из одной структуры в другую.
Кодирование данных
Код – система условных обозначений или сигналов.
Длина кода – количество знаков, используемых для представления кодируемой информации
Кодирование данных – это процесс формирования определенного представления информации.
Декодирование – расшифровка кодированных знаков, преобразование кода символа в его изображение
Двоичное кодирование – кодирование информации в виде 0 и 1.
В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Любой способ кодирования характеризуется наличием основы (алфавит, система координат, основание системы счисления и т.д.) и правил конструирования информационных образов на этой основе. Кодирование числовых данных осуществляется с помощью системы счисления.
Двоичное кодирование
Представление информации в двоичной системе использовалось человеком с давних времен. Так,жители островов Полинезии передавали необходимую информацию при помощи барабанов: чередование звонких и глухих ударов. Звук над поверхностью воды распространялся на достаточно большое расстояние, таким образом «работал» полинезийский телеграф. В телеграфе в XIX–XX веках информация передавалась с помощью азбуки Морзе – в виде последовательности из точек и тире. Часто мы договариваемся открывать входную дверь только по «условному сигналу» – комбинации коротких и длинных звонков.
Самюэл Морзе в 1838 г. изобрел код – телеграфную азбуку – систему кодировки символов короткими и длинными посылками для передачи их по линиям связи, известную как «код Морзе» или «морзянка». Современный вариант международного «кода Морзе» (International Morse) появился совсем недавно – в 1939 году, когда была проведена последняя корректировка.
Своя система существует и в вычислительной технике - она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по-английски - binary digit или сокращенно bit (бит). Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т.п.).
Кодирование чисел
Вопрос о кодировании чисел возникает по той причине, что в машину нельзя либо нерационально вводить числа в том виде, в котором они изображаются человеком на бумаге. Во-первых, нужно кодировать знак числа. Во-вторых, по различным причинам, которые будут рассмотрены ниже, приходится иногда кодировать и остальную часть числа.
Кодирование целых чисел производиться через их представление в двоичной системе счисления: именно в этом виде они и помещаются в ячейке. Один бит отводиться при этом для представления знака числа (нулем кодируется знак "плюс", единицей - "минус").
Для кодирования действительных чисел существует специальный формат чисел с плавающей запятой. Число при этом представляется в виде: N = M * qp, где M - мантисса, p - порядок числа N, q - основание системы счисления. Если при этом мантисса M удовлетворяет условию 0,1 <= | M | <= 1 то число N называют нормализованным.
Кодирование текста
Для кодирования букв и других символов, используемых в печатных документах, необходимо закрепить за каждым символом числовой номер – код. В англоязычных странах используются 26 прописных и 26 строчных букв (A … Z, a … z), 9 знаков препинания (. , : ! " ; ? ()), пробел, 10 цифр, 5 знаков арифметических действий (+,-,*, /, ^) и специальные символы (№, %, _, #, $, &, >, <, |, \) – всего чуть больше 100 символов. Таким образом, для кодирования этих символов можно ограничиться максимальным 7-разрядным двоичным числом (от 0 до 1111111, в десятичной системе счисления – от 0 до 127).
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части – растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element). Код пиксела содержит информации о его цвете.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения – линия. Каждый элемент векторного изображения является объектом, который описывается с помощью математических уравнении. Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Кодирование звука
На компьютере работать со звуковыми файлами начали в 90-х годах. В основе цифрового кодирования звука лежит – процесс преобразования колебаний воздуха в колебания электрического тока и последующая дискретизация аналогового электрического сигнала. Кодирование и воспроизведение звуковой информации осуществляется с помощью специальных программ (редактор звукозаписи).
Временная дискретизация – способ преобразования звука в цифровую форму путем разбивания звуковой волны на отдельные маленькие временные участки где амплитуды этих участков квантуются (им присваивается определенное значение).
Это производится с помощью аналого-цифрового преобразователя, размещенного на звуковой плате. Таким образом, непрерывная зависимость амплитуды сигнала от времени заменяется дискретной последовательностью уровней громкости. Современные 16-битные звуковые карты кодируют 65536 различных уровней громкости или 16-битную глубину звука (каждому значению амплитуды звук. сигнала присваивается 16-битный код)
Качество кодирование звука зависит от:
глубины кодирования звука - количество уровней звука
частоты дискретизации – количество изменений уровня сигнала в единицу
В чем разница между кодированием и шифрованием?
Шифрование - это способ изменения сообщения, обеспечивающее сокрытие его содержимого. Кодирование - это преобразование обычного, понятного, текста в код. При этом подразумевается, что существует взаимно однозначное соответствие между символами текста и символьного кода - в этом принципиальное отличие кодирования от шифрования.
Структура данных - программная единица, позволяющая хранить и обрабатывать множество однотипных и/или логически связанных данных в вычислительной технике. Для добавления, поиска, изменения и удаления данных структура данных предоставляет некоторый набор функций, составляющих её интерфейс. Структура данных часто является реализацией какого-либо абстрактного типа данных.
При разработке программного обеспечения большую роль играет проектирование хранилища данных и представление всех данных в виде множества связанных структур данных.
Хорошо спроектированное хранилище данных оптимизирует использование ресурсов (таких как время выполнения операций, используемый объём оперативной памяти, число обращений к дисковым накопителям), требуемых для выполнения наиболее критичных операций.
Структуры данных формируются с помощью типов данных, ссылок и операций над ними в выбранном языке программирования.
Различные виды структур данных подходят для различных приложений; некоторые из них имеют узкую специализацию для определённых задач. Например, B-деревья обычно подходят для создания баз данных, в то время как хеш-таблицы используются повсеместно для создания различного рода словарей, например, для отображения доменных имён в интернет-адреса компьютеров.
При разработке программного обеспечения сложность реализации и качество работы программ существенно зависит от правильного выбора структур данных. Это понимание дало начало формальным методам разработки и языкам программирования, в которых именно структуры данных, а не алгоритмы, ставятся во главу архитектуры программного средства. Большая часть таких языков обладает определённым типом модульности, позволяющим структурам данных безопасно переиспользоваться в различных приложениях. Объектно-ориентированные языки, такие как Java, C# и C++, являются примерами такого подхода.
Многие классические структуры данных представлены в стандартных библиотеках языков программирования или непосредственно встроены в языки программирования. Например, структура данных хэш-таблица встроена в языки программирования Lua, Perl, Python, Ruby, Tcl и др. Широко используется стандартная библиотека шаблонов STL языка C++.
Фундаментальными строительными блоками для большей части структур данных являются массивы, записи (см. конструкцию struct в языке Си и конструкцию record в языке Паскаль), размеченные объединения (см. конструкцию union в языке Си) и ссылки. Например, структура данных двусвязный список, может быть построена с помощью записей и зануляемых ссылок, а именно, каждая запись будет предоставлять блок данных (узел, node), содержащий ссылки на «левый» и «правый» узлы, а также сами хранимые данные.
1.1.1.Основные типы данных.
Данные, хранящиеся в памяти ЭВМ представляют собой совокупность нулей и едениц (битов). Биты объединяются в последовательности: байты, слова и т.д. Каждому участку оперативной памяти, который может вместить один байт или слово, присваивается порядковый номер (адрес).
Какой смысл заключен в данных, какими символами они выражены - буквенными или цифровыми, что означает то или иное число - все это определяется программой обработки. Все данные необходимые для решения практических задач подразделяются на несколько типов, причем понятие тип связывается не только с представлением данных в адресном пространстве, но и со способом их обработки.
Любые данные могут быть отнесены к одному из двух типов: основному (простому), форма представления которого определяется архитектурой ЭВМ, или сложному, конструируемому пользователем для решения конкретных задач.
Данные простого типа это - символы, числа и т.п. элементы, дальнейшее дробление которых не имеет смысла. Из элементарных данных формируются структуры (сложные типы) данных.
Некоторые структуры:
Массив(функция с конечной областью определения) - простая совокупность элементов данных одного типа, средство оперирования группой данных одного типа. Отдельный элемент массива задается индексом. Массив может быть одномерным, двумерным и т.д. Разновидностями одномерных массивов переменной длины являются структуры типа кольцо, стек, очередь и двухсторонняя очередь.
Запись(декартово произведение) - совокупность элементов данных разного типа. В простейшем случае запись содержит постоянное количество элементов, которые называют полями. Совокупность записей одинаковой структуры называется файлом. (Файлом называют также набор данных во внешней памяти, например, на магнитном диске). Для того, чтобы иметь возможность извлекать из файла отдельные записи, каждой записи присваивают уникальное имя или номер, которое служит ее идентификатором и располагается в отдельном поле. Этот идентификатор называют ключом.
Такие структуры данных как массив или запись занимают в памяти ЭВМ постоянный объем, поэтому их называют статическими структурами. К статическим структурам относится также множество.
Имеется ряд структур, которые могут изменять свою длину - так называемые динамические структуры. К ним относятся дерево, список, ссылка.
Важной структурой, для размещения элементов которой требуется нелинейное адресное пространство является дерево. Существует большое количество структур данных, которые могут быть представлены как деревья. Это, например, классификационные, иерархические, рекурсивные и др. структуры.
3. Система счисле́ния - символический метод записи чисел, представление чисел с помощью письменных знаков.
Система счисления:
даёт представления множества чисел (целых и/или вещественных);
даёт каждому числу уникальное представление (или, по крайней мере, стандартное представление);
отражает алгебраическую и арифметическую структуру чисел.
Системы счисления подразделяются на позиционные, непозиционные и смешанные.
Чем больше основание системы счисления, тем меньшее количество разрядов (то есть записываемых цифр) требуется при записи числа в позиционных системах счисления.
Позиционные системы счисления
Основная статья: Позиционная система счисления
В позиционных системах счисления один и тот же числовой знак (цифра) в записи числа имеет различные значения в зависимости от того места (разряда), где он расположен. Изобретение позиционной нумерации, основанной на поместном значении цифр, приписывается шумерам и вавилонянам; развита была такая нумерация индусами и имела неоценимые последствия в истории человеческой цивилизации. К числу таких систем относится современная десятичная система счисления, возникновение которой связано со счётом на пальцах. В средневековой Европе она появилась через итальянских купцов, в свою очередь заимствовавших её у мусульман.
Под позиционной системой счисления обычно понимается b-ричная система счисления, которая определяется целым числом b > 1, называемым основанием системы счисления. Целое число x в b-ричной системе счисления представляется в виде конечной линейной комбинации степеней числа b:
Где ak - это целые числа, называемые цифрами, удовлетворяющие неравенству.
Каждая степень bk в такой записи называется весовым коэффициентом разряда. Старшинство разрядов и соответствующих им цифр определяется значением показателя k (номером разряда). Обычно для ненулевого числа x требуют, чтобы старшая цифра an − 1 в его b-ричном представлении была также ненулевой.
Если не возникает разночтений (например, когда все цифры представляются в виде уникальных письменных знаков), число x записывают в виде последовательности его b-ричных цифр, перечисляемых по убыванию старшинства разрядов слева направо:
Например, число сто три представляется в десятичной системе счисления в виде:
Наиболее употребляемыми в настоящее время позиционными системами являются:
1 - единичная (счёт на пальцах, зарубки, узелки «на память» и др.);
2 - двоичная (в дискретной математике, информатике, программировании);
3 - троичная;
8 - восьмеричная;
10 - десятичная (используется повсеместно);
12 - двенадцатеричная (счёт дюжинами);
16 - шестнадцатеричная (используется в программировании, информатике);
60 - шестидесятеричная (единицы измерения времени, измерение углов и, в частности, координат, долготы и широты).
4. Файл (англ. file - папка, скоросшиватель) - концепция в вычислительной технике: сущность, позволяющая получить доступ к какому-либо ресурсу вычислительной системы и обладающая рядом признаков:
фиксированное имя (последовательность символов, число или что-то иное, однозначно характеризующее файл);
определённое логическое представление и соответствующие ему операции чтения/записи.
Может быть любой - от последовательности бит до базы данных с произвольной организацией или любым промежуточным вариантом.
Первому случаю соответствуют операции чтения/записи потока и/или массива (то есть последовательные или с доступом по индексу), второму - команды СУБД. Промежуточные варианты - чтение и разбор всевозможных форматов файлов.
В информатике используется следующее определение: файл - поименованная совокупность байтов произвольной длины, находящихся на носителе информации.
В отличие от переменной, файл (в частности, его имя) имеет смысл вне конкретной программы. Работа с файлами реализуется средствами операционных систем.
Ресурсами, доступными через файлы, в принципе, может быть что угодно, представимое в цифровом виде. Чаще всего в их перечень входят:
области данных (необязательно на диске);
устройства (как физические, так и виртуальные);
потоки данных (в частности, вход или выход процесса);
сетевые ресурсы;
объекты операционной системы.
Файлы первого типа исторически возникли первыми и распространены наиболее широко, поэтому часто «файлом» называют и область данных, соответствующую имени.